
[코드 실행] AudioToken 코드 실행
https://github.com/guyyariv/AudioToken
1. Inference 코드 실행
1.1. 코드 분석
- AudioToken의 구조를 이해하기 위해 코드에 주석을 상세히 작성하며, 함수가 어떤 역할을 하고, 어떤 구조를 가지는지 분석하였다.
-
Inference.py
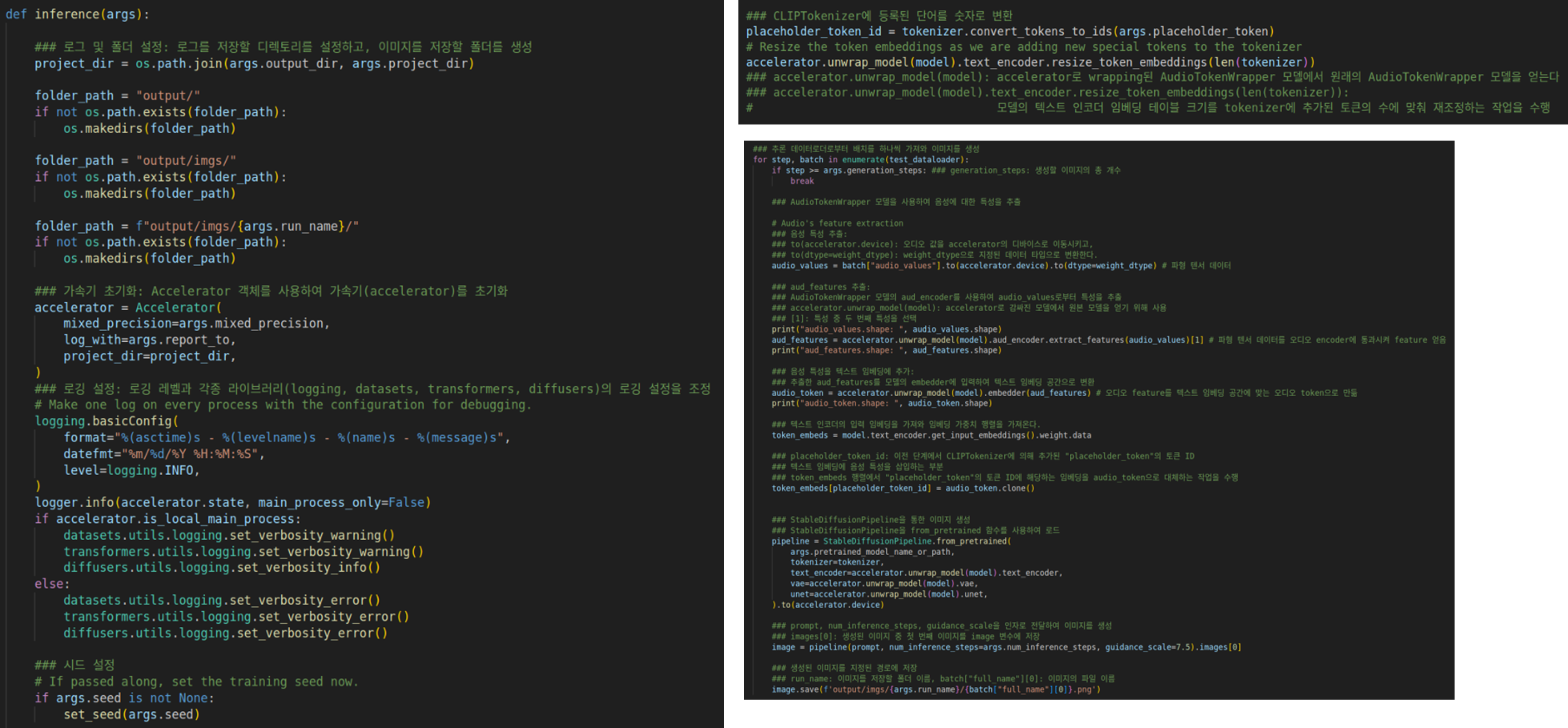
-
-
dataloader.py
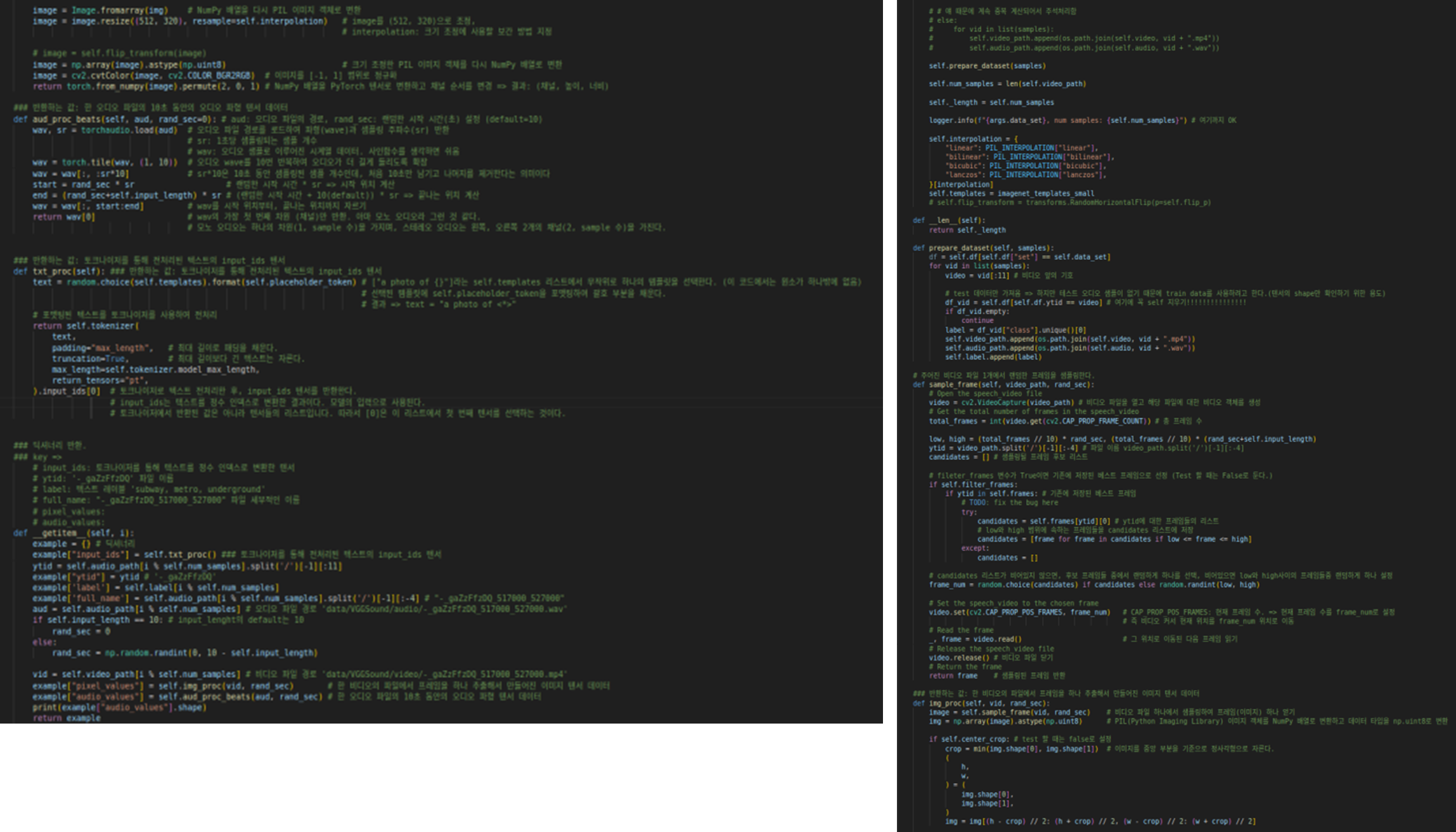
1.2. Inference.py 실행 중의 오류 발생 사항들
-
쉘 스크립트에서 “\” 뒤에 공백이 들어가면 오류나 나타난다. 네 번째 줄의 역슬래시 뒤에 공백이 추가되어 오류가 발생했다. 제거해주니 제대로 작동한다.
accelerate launch inference.py \ --pretrained_model_name_or_path=$MODEL_NAME \ --train_data_dir=$DATA_DIR \ --output_dir=$OUTPUT_DIR \ --learned_embeds=$LEARNED_EMBEDS - inference.py 파일에는 test_data_dir 변수가 없는데, 깃허브에 test_data_dir 변수를 스크립트에 작성하라고 해서 애먹었다.
-
test_data_dir 변수를 train_data_dir으로 바꾸었다. 그리고 train_data_dir에 vggsound video 데이터셋을 다운받고 해당 경로를 train_data_dir에 입력했다.
accelerate launch inference.py \ --pretrained_model_name_or_path=$MODEL_NAME \ --train_data_dir=$DATA_DIR \ --output_dir=$OUTPUT_DIR \ --learned_embeds=$LEARNED_EMBEDS
-
- inference 스크립트를 실행하려고 하자, 이번에는
TypeError: Accelerator.**init**() got an unexpected keyword argument 'logging_dir'오류가 발생했다.-
구글링해서 찾아보니 accelerator가 업데이트되면서
logging_dir가project_dir으로 변경되었다고 한다. 다운그레이드를 하려고 했지만, 이 변수 하나만 오류라고 떠서 인자 이름만 바꿔줬다.
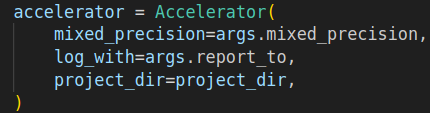
-
-
lora_learned_embeds를 사용하지 않으려고 inference.py의 인자 전달 부분에서 lora=False를 기본값으로 변경하였다.

- label이 정의되어 있지 않기에 발생한 오류:
- 이 부분에서
AttributeError: 'AudioTokenVGGSound' object has no attribute 'label’error가 발생하는데, 그 이유가AudioTokenVGGSound에 label이 정의되어 있지 않기 때문이다. -
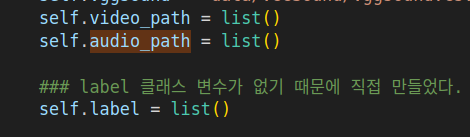
아래의 self.label이 정의되어있지 않아 오류가 발생하였다.
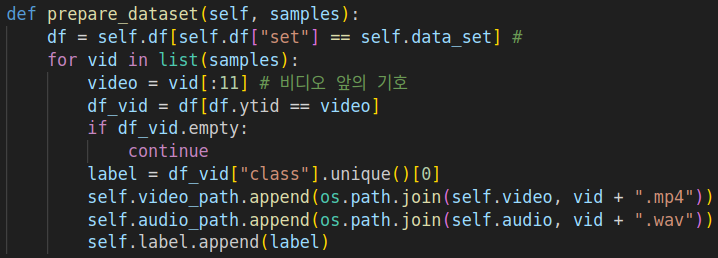
- 우선 맘대로 self.label을 만들 수는 없으니 self.label이 하는 역할을 알아보자
- self.label: 매 비디오에 해당하는 class를 담는 리스트이다.
- label 클래스 변수가 없기 때문에 이 위치에 직접 만들었다. (dataloader.py)
- self.label: 매 비디오에 해당하는 class를 담는 리스트이다.
-
그리고 현재 샘플 데이터에 있는 비디오와 오디오 데이터는 train 전용이다. vggsound 데이터셋을 다운받았을 때, 오디오 데이터가 없었기 때문에 train을 사용한다. (텐서의 shape만 확인하는 용도)
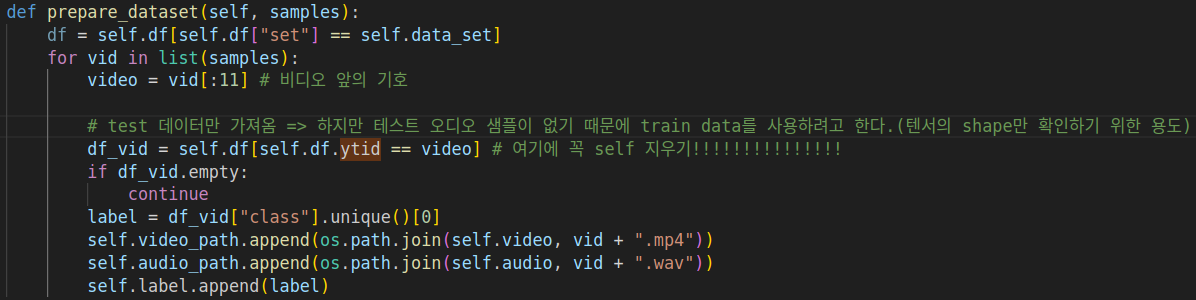
- 원본 코드로 돌아갈 때, 꼭 self를 지우자!!
- 우선 맘대로 self.label을 만들 수는 없으니 self.label이 하는 역할을 알아보자
- 이 부분에서
- 이런 오류가 났다
example['label'] = self.label[i % self.num_samples] IndexError: list index out of range-
아래 코드와 prepared_dataset이 중복 연산이 되어, 밑에 얘를 주석처리하여 해결하였다.

-
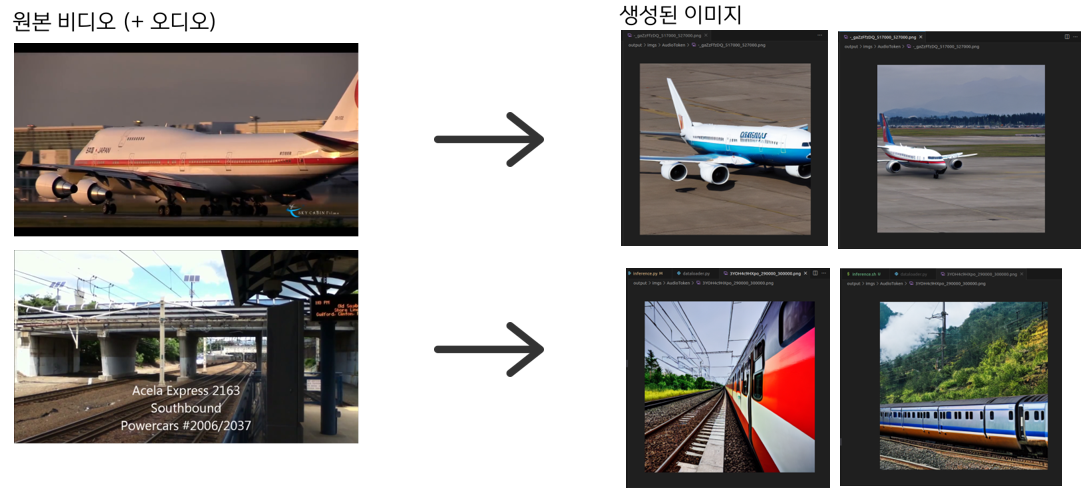
1.3. Inference 실행 결과
2. AudioToken 모델의 Encoder에 audio가 어떻게 들어가는지 Shape 확인
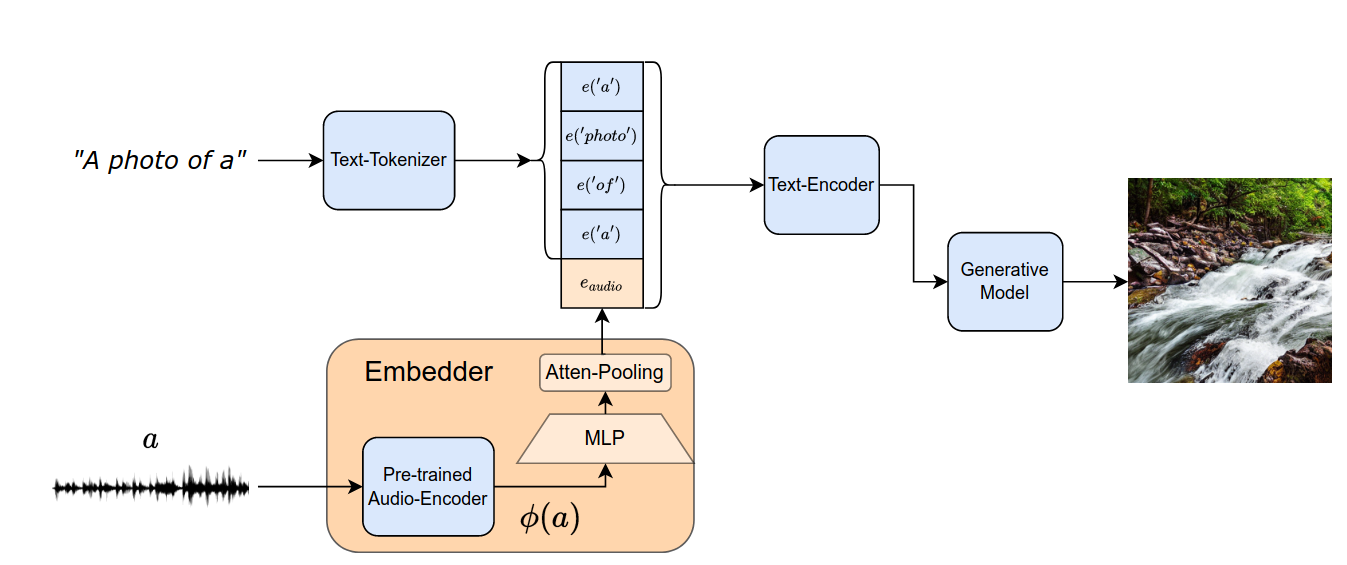
2.1. 오디오 전처리 과정

aud_proc_beats이 함수를 통해 오디오가 변형되었다.
2.2. 결과

- 텐서로 변환 후: torch.Size([160000])
- Pre-trained Auto-Encoder 통과 후: torch.Size([1, 496, 2304])
- Attention-Pooling 후: torch.Size([1, 768])
댓글남기기