
[데이터셋 조사] audio captioning dataset & video captioning dataset 조사
1. video captioning dataset
-
MSR-VTT

MSR-VTT (Microsoft Research Video to Text) is a large-scale dataset for the open domain video captioning, which consists of 10,000 video clips from 20 categories, and each video clip is annotated with 20 English sentences by Amazon Mechanical Turks. There are about 29,000 unique words in all captions. The standard splits uses 6,513 clips for training, 497 clips for validation, and 2,990 clips for testing.
Papers with Code - MSR-VTT Dataset
-
WebVid

WebVid contains 10 million video clips with captions, sourced from the web. The videos are diverse and rich in their content.
Both the full 10M set and a 2.5M subset is available for download: https://github.com/m-bain/webvid-dataset
Papers with Code - WebVid Dataset
-
HD-VILA-100M Dataset
HD-VILA-100M is a large-scale, high-resolution, and diversified video-language dataset to facilitate the multimodal representation learning.
https://github.com/microsoft/XPretrain/tree/main/hd-vila-100m
-
MSVD (Microsoft Research Video Description Corpus)

The Microsoft Research Video Description Corpus (MSVD) dataset consists of about 120K sentences collected during the summer of 2010. Workers on Mechanical Turk were paid to watch a short video snippet and then summarize the action in a single sentence. The result is a set of roughly parallel descriptions of more than 2,000 video snippets. Because the workers were urged to complete the task in the language of their choice, both paraphrase and bilingual alternations are captured in the data.
Papers with Code - MSVD Dataset
-
HowTo100M

HowTo100M is a large-scale dataset of narrated videos with an emphasis on instructional videos where content creators teach complex tasks with an explicit intention of explaining the visual content on screen. HowTo100M features a total of:
- 136M video clips with captions sourced from 1.2M Youtube videos (15 years of video)
- 23k activities from domains such as cooking, hand crafting, personal care, gardening or fitness
Each video is associated with a narration available as subtitles automatically downloaded from Youtube.
Papers with Code - HowTo100M Dataset
-
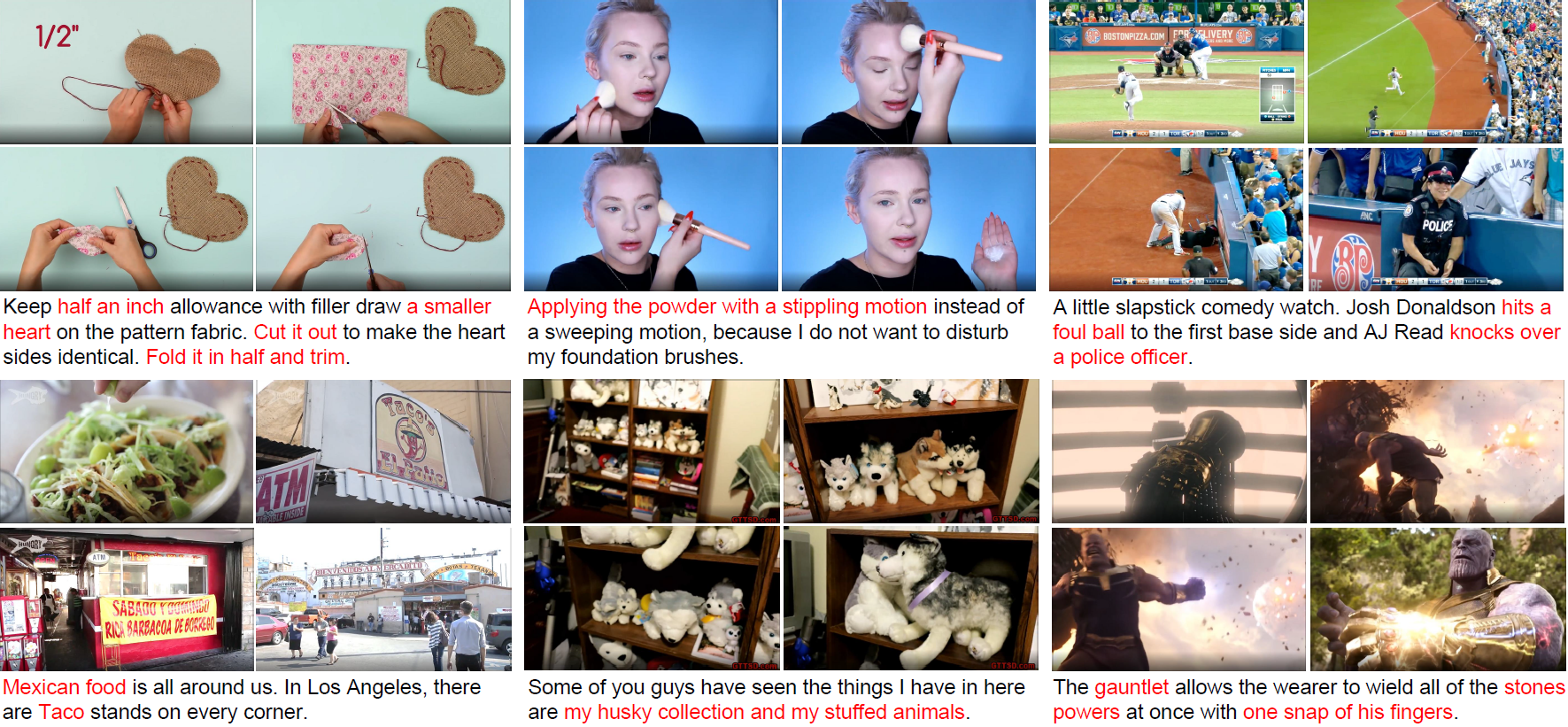
ActivityNet Captions
The ActivityNet Captions dataset is built on ActivityNet v1.3 which includes 20k YouTube untrimmed videos with 100k caption annotations. The videos are 120 seconds long on average. Most of the videos contain over 3 annotated events with corresponding start/end time and human-written sentences, which contain 13.5 words on average. The number of videos in train/validation/test split is 10024/4926/5044, respectively.
Papers with Code - ActivityNet Captions Dataset
-
YouCook, YouCook2

YouCook2 is the largest task-oriented, instructional video dataset in the vision community. It contains 2000 long untrimmed videos from 89 cooking recipes; on average, each distinct recipe has 22 videos. The procedure steps for each video are annotated with temporal boundaries and described by imperative English sentences (see the example below). The videos were downloaded from YouTube and are all in the third-person viewpoint. All the videos are unconstrained and can be performed by individual persons at their houses with unfixed cameras. YouCook2 contains rich recipe types and various cooking styles from all over the world.
Papers with Code - YouCook Dataset
Papers with Code - YouCook2 Dataset
-
VATEX

VATEX is multilingual, large, linguistically complex, and diverse dataset in terms of both video and natural language descriptions. It has two tasks for video-and-language research: (1) Multilingual Video Captioning, aimed at describing a video in various languages with a compact unified captioning model, and (2) Video-guided Machine Translation, to translate a source language description into the target language using the video information as additional spatiotemporal context.
Papers with Code - VATEX Dataset
-
TGIF (Tumblr GIF)

The Tumblr GIF (TGIF) dataset contains 100K animated GIFs and 120K sentences describing visual content of the animated GIFs. The animated GIFs have been collected from Tumblr, from randomly selected posts published between May and June of 2015. The dataset provides the URLs of animated GIFs. The sentences are collected via crowdsourcing, with a carefully designed annotation interface that ensures high quality dataset. There is one sentence per animated GIF for the training and validation splits, and three sentences per GIF for the test split. The dataset can be used to evaluate animated GIF/video description techniques.
Papers with Code - TGIF Dataset
-
VALUE (Video-And-Language Understanding Evaluation)
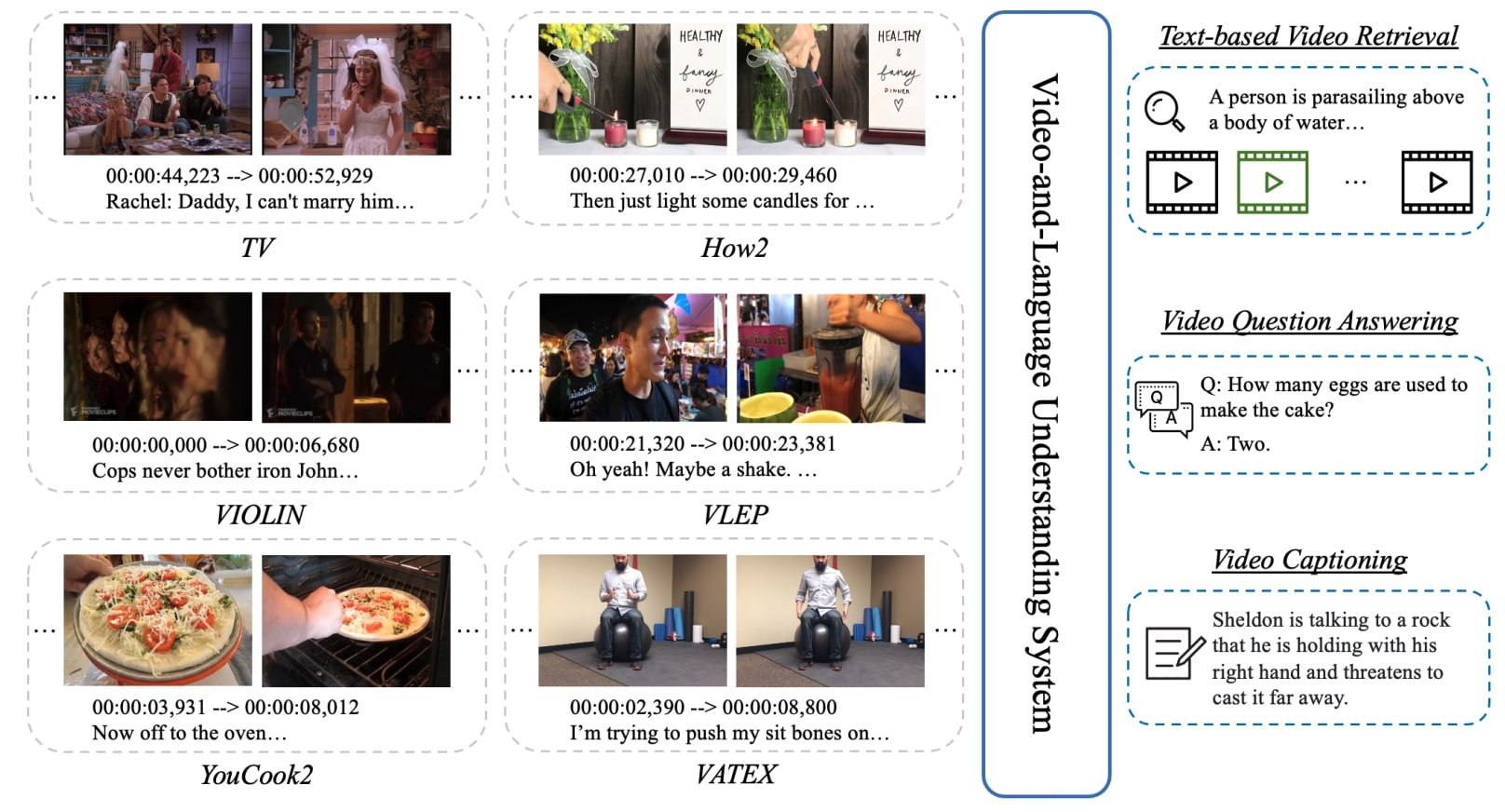
VALUE is a Video-And-Language Understanding Evaluation benchmark to test models that are generalizable to diverse tasks, domains, and datasets. It is an assemblage of 11 VidL (video-and-language) datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks.
Papers with Code - VALUE Dataset
-
LSMDC (Large Scale Movie Description Challenge)

This dataset contains 118,081 short video clips extracted from 202 movies. Each video has a caption, either extracted from the movie script or from transcribed DVS (descriptive video services) for the visually impaired. The validation set contains 7408 clips and evaluation is performed on a test set of 1000 videos from movies disjoint from the training and val sets.
Papers with Code - LSMDC Dataset
-
DiDeMo (Distinct Describable Moments)

The Distinct Describable Moments (DiDeMo) dataset is one of the largest and most diverse datasets for the temporal localization of events in videos given natural language descriptions. The videos are collected from Flickr and each video is trimmed to a maximum of 30 seconds. The videos in the dataset are divided into 5-second segments to reduce the complexity of annotation. The dataset is split into training, validation and test sets containing 8,395, 1,065 and 1,004 videos respectively. The dataset contains a total of 26,892 moments and one moment could be associated with descriptions from multiple annotators. The descriptions in DiDeMo dataset are detailed and contain camera movement, temporal transition indicators, and activities. Moreover, the descriptions in DiDeMo are verified so that each description refers to a single moment.
Papers with Code - DiDeMo Dataset
-
CrossTask

CrossTask dataset contains instructional videos, collected for 83 different tasks. For each task an ordered list of steps with manual descriptions is provided. The dataset is divided in two parts: 18 primary and 65 related tasks. Videos for the primary tasks are collected manually and provided with annotations for temporal step boundaries. Videos for the related tasks are collected automatically and don’t have annotations.
Papers with Code - CrossTask Dataset
-
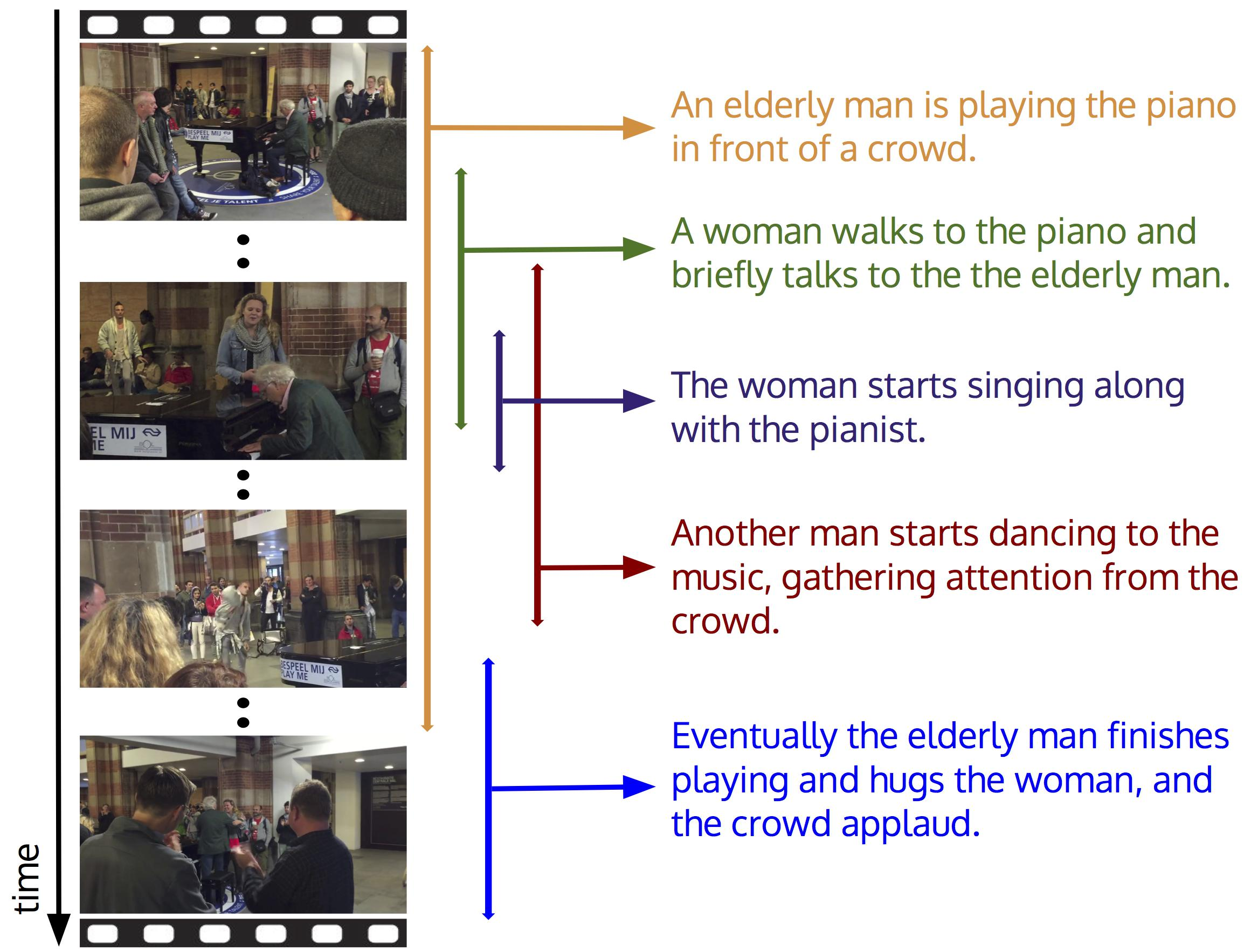
Violin (VIdeO-and-Language INference)

Video-and-Language Inference is the task of joint multimodal understanding of video and text. Given a video clip with aligned subtitles as premise, paired with a natural language hypothesis based on the video content, a model needs to infer whether the hypothesis is entailed or contradicted by the given video clip. The Violin dataset is a dataset for this task which consists of 95,322 video-hypothesis pairs from 15,887 video clips, spanning over 582 hours of video. These video clips contain rich content with diverse temporal dynamics, event shifts, and people interactions, collected from two sources: (i) popular TV shows, and (ii) movie clips from YouTube channels. Papers with Code - Violin Dataset
-
TVC (TV show Captions)

TV show Caption is a large-scale multimodal captioning dataset, containing 261,490 caption descriptions paired with 108,965 short video moments. TVC is unique as its captions may also describe dialogues/subtitles while the captions in the other datasets are only describing the visual content.
Papers with Code - TVC Dataset
-
M-VAD Names (M-VAD Names Dataset)
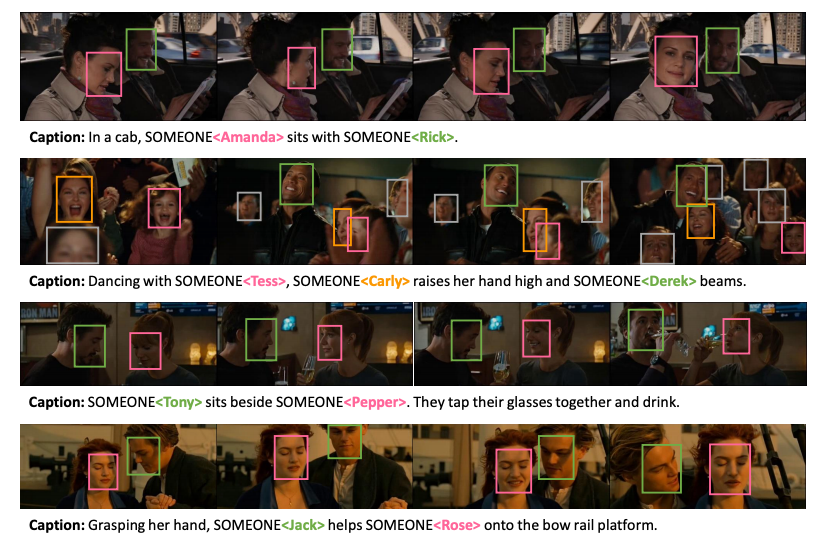
The dataset contains the annotations of characters’ visual appearances, in the form of tracks of face bounding boxes, and the associations with characters’ textual mentions, when available. The detection and annotation of the visual appearances of characters in each video clip of each movie was achieved through a semi-automatic approach. The released dataset contains more than 24k annotated video clips, including 63k visual tracks and 34k textual mentions, all associated with their character identities.
Papers with Code - M-VAD Names Dataset
-
ViTT (Video Timeline Tags)

The ViTT dataset consists of human produced segment-level annotations for 8,169 videos. Of these, 5,840 videos have been annotated once, and the rest of the videos have been annotated twice or more. A total of 12,461 sets of annotations are released. The videos in the dataset are from the Youtube-8M dataset.
Papers with Code - ViTT Dataset
-
NSVA (NBA dataset for Sports Video Analysis)
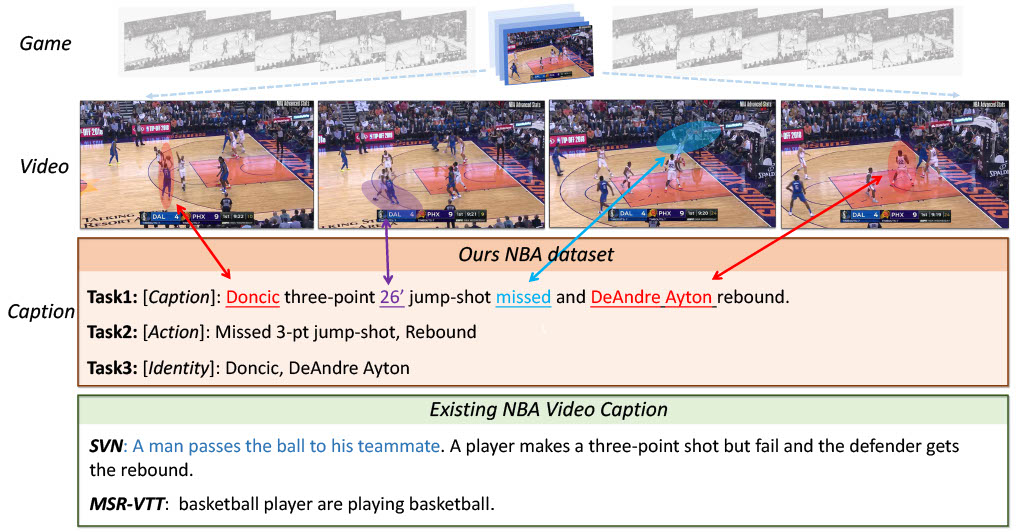
NVSA is a large-scale NBA dataset for Sports Video Analysis (NSVA) with a focus on sports video captioning. This dataset consists of more than 32K video clips and it is also designed to address two additional tasks, namely fine-grained sports action recognition and salient player identification.
Papers with Code - NSVA Dataset
-
Kinetics-GEB+
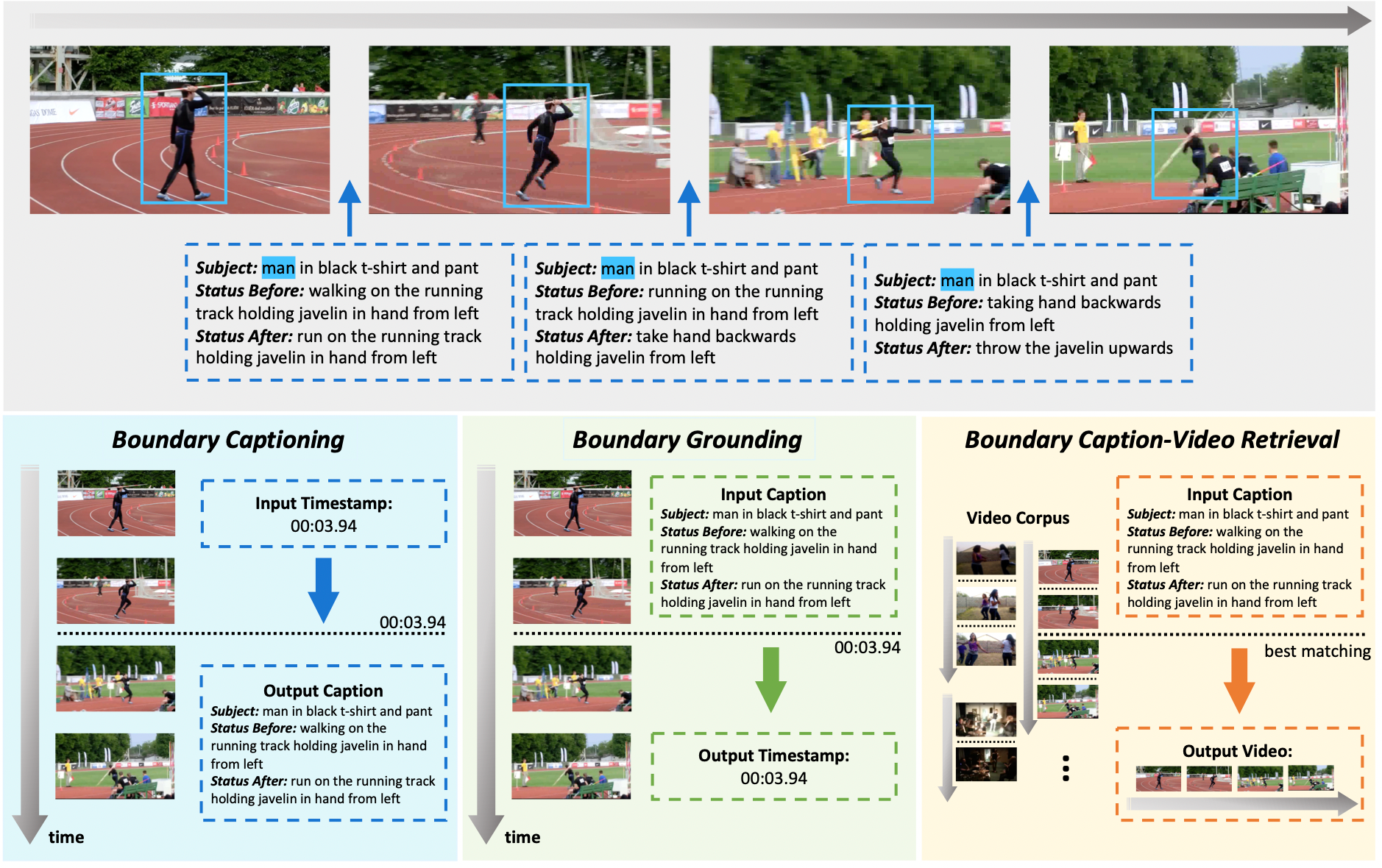
Kinetics-GEB+ (Generic Event Boundary Captioning, Grounding and Retrieval) is a dataset that consists of over 170k boundaries associated with captions describing status changes in the generic events in 12K videos.
Papers with Code - Kinetics-GEB+ Dataset
2. audio captioning dataset
- Models with Datasets
- Make-An-Audio 2: Temporal-Enhanced Text-to-Audio Generation
- AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models
- AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
- Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
- DataSet
-
AudioSet
Audioset is an audio event dataset, which consists of over 2M human-annotated 10-second video clips. These clips are collected from YouTube, therefore many of which are in poor-quality and contain multiple sound-sources. A hierarchical ontology of 632 event classes is employed to annotate these data, which means that the same sound could be annotated as different labels. For example, the sound of barking is annotated as Animal, Pets, and Dog. All the videos are split into Evaluation/Balanced-Train/Unbalanced-Train set.
Papers with Code - AudioSet Dataset
-
Clotho
Clotho is an audio captioning dataset, consisting of 4981 audio samples, and each audio sample has five captions (a total of 24 905 captions). Audio samples are of 15 to 30 s duration and captions are eight to 20 words long.
-
AudioCaps
AudioCaps is a dataset of sounds with event descriptions that was introduced for the task of audio captioning, with sounds sourced from the AudioSet dataset. Annotators were provided the audio tracks together with category hints (and with additional video hints if needed).

Papers with Code - AudioCaps Dataset
-
MusicCaps
MusicCaps is a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts. For each 10-second music clip, MusicCaps provides:
1) A free-text caption consisting of four sentences on average, describing the music and
2) A list of music aspects, describing genre, mood, tempo, singer voices, instrumentation, dissonances, rhythm, etc.
Papers with Code - MusicCaps Dataset
-
UrbanSound8K
Urban Sound 8K is an audio dataset that contains 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes: air_conditioner, car_horn, children_playing, dog_bark, drilling, enginge_idling, gun_shot, jackhammer, siren, and street_music. The classes are drawn from the urban sound taxonomy. All excerpts are taken from field recordings uploaded to www.freesound.org.
Papers with Code - UrbanSound8K Dataset
-
댓글남기기