
[논문 조사] Video generation에서 Depth 사용하는 논문 조사
1. [ICLR 2023] PV3D: A 3D Generative Model for Portrait Video Generation
https://arxiv.org/pdf/2212.06384
- 직접적인 depth를 사용하진 않지만, 2D model을 사용하여, 3D 구현
- contribution
- To our best knowledge, PV3D is the first method that is capable to generate a large variety of 3D-aware portrait videos with high-quality appearance, motions, and geometry.
- We propose a novel temporal tri-plane based video generation framework that can synthesize 3D-aware portrait videos by learning from 2D videos only.
-
We propose a novel temporal tri-plane based video generation framework that can synthesize 3D-aware portrait videos by learning from 2D videos only.

- contribution
2. [CVPR 2022] Depth-Aware Generative Adversarial Network for Talking Head Video Generation
Paper: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
- Depth 사용 방식
- depth maps을 기반으로 sparse facial keypoints를 찾아 사람 얼굴의 특징적인 움직임을 포착한다.
- “Based on the learned dense depth maps, we further propose to leverage them to estimate sparse facial keypoints that capture the critical movement of the human head.”
- depth는 3D-aware cross-modal attention에서 모션을 학습하는데 사용된다.
- In a more dense way, the depth is also utilized to learn 3D-aware cross-modal (i.e. appearance and depth) attention to guide the generation of motion fields for warping source image representations.
3. DaGAN++: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
https://arxiv.org/pdf/2305.06225
- Depth-Aware Generative Adversarial Network for Talking Head Video Generation
논문의 후속 연구이다.
- we develop a 3D-aware cross-modal (i.e., appearance and depth) attention mechanism, which can be applied to each generation layer, to capture facial geometries in a coarse-to-fine manner.

- we develop a 3D-aware cross-modal (i.e., appearance and depth) attention mechanism, which can be applied to each generation layer, to capture facial geometries in a coarse-to-fine manner.
4. GD-VDM: Generated Depth for better Diffusion-based Video Generation
https://arxiv.org/pdf/2306.11173
- GD-VDM is based on a two-phase generation process involving generating depth videos followed by a novel diffusion Vid2Vid model that generates a coherent real-world video.
- ⇒ depth video를 생성하고, 생성된 depth video를 기반으로 일관된 비디오를 생성한다.
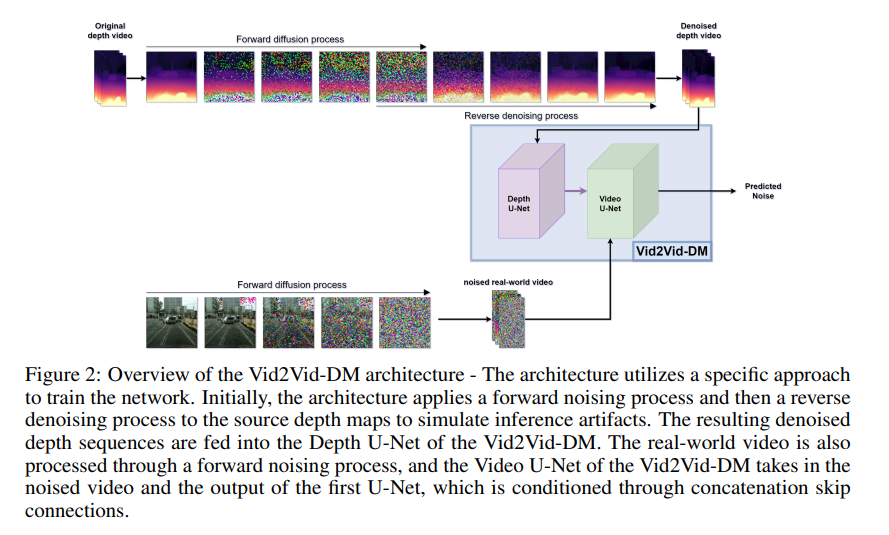
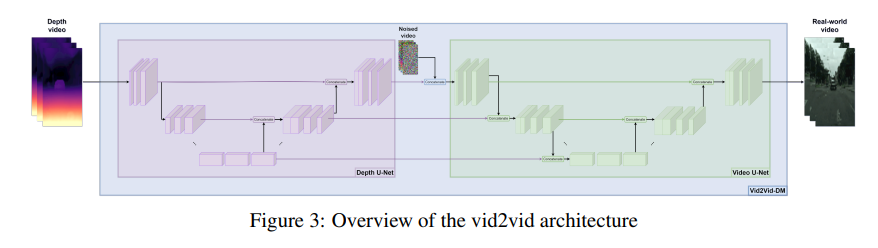
- ⇒ depth video를 생성하고, 생성된 depth video를 기반으로 일관된 비디오를 생성한다.
5. Pix2video: Video editing using image diffusion
https://arxiv.org/pdf/2303.12688
-
depth-conditioned Stable Diffusion 모델을 사용하였다.




Structure-guided Video Generation
- 6, 7, 8, 9번 논문들은 공통적으로 Structure-guided Video Generation 분야에 속한다.
- depth estimate하는데에 모두 Midas depth estimation model을 사용
- 또한 생성 모델로 diffusion model을 사용
6. Structure and content-guided video synthesis with diffusion models
https://arxiv.org/pdf/2302.03011
- 비디오 editing 분야이지만, 인용이 많이 된 듯 하여 가져왔다.
-
user-provided content와 structure representations의 충돌을 해결하기 위해 depth estimation을 도입하였다.

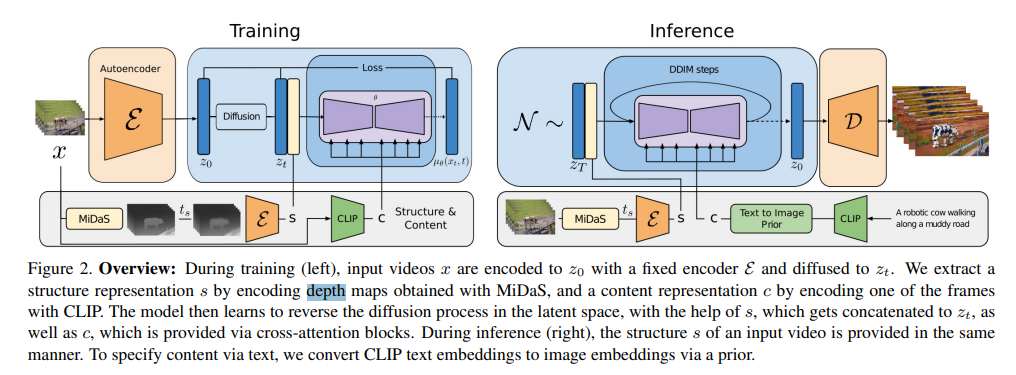
- Training (depth 부분만 설명)
- Midas depth estimation model을 통해 depth maps를 얻는다.
- depth maps를 인코딩하여 structure representation s를 추출한다. s를 이용해서 reverse process를 학습한다.
- Training (depth 부분만 설명)
7. Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation
https://arxiv.org/pdf/2307.06940
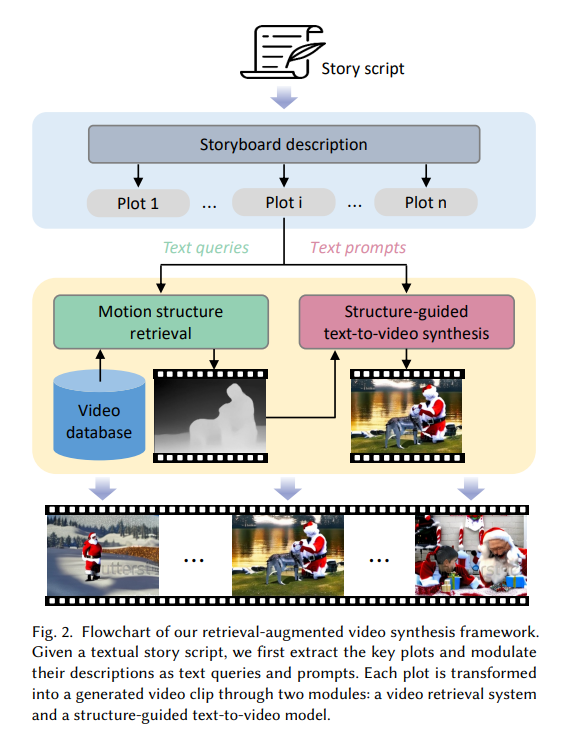
- 과정
- Story Script에서 핵심 plots를 추출한다.
- plots의 descriptions을 text queries와 prompts에 맞게 조정한다.
- 각 plot은 두 모듈에 들어간다. (a video retrieval system과 a structure-guided text-to-video model )
- a structure-guided text-to-video model
- text query에 맞는 video 후보들을 얻는다. 이때, video 후보가 외적으로 잘 맞지 않는 경우를 대비하여, depth estimation algorithm을 적용한다.
- depth estimator로는 Midas depth estimation model을 사용한다.
- conditional LDM to learn controllable video synthesis
- motion structure와 text prompt 모두 조건으로 들어간다.
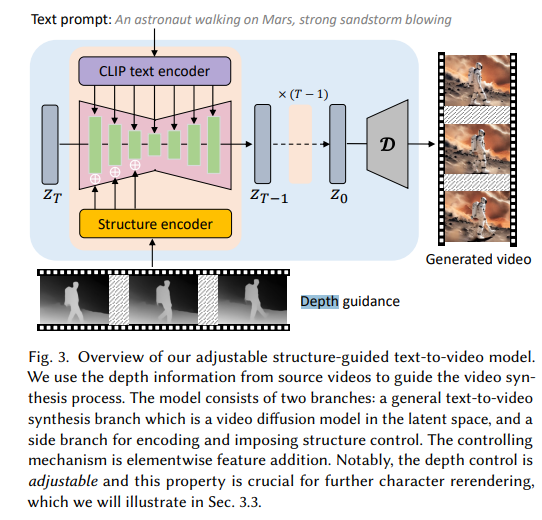
- motion structure와 text prompt 모두 조건으로 들어간다.
- text query에 맞는 video 후보들을 얻는다. 이때, video 후보가 외적으로 잘 맞지 않는 경우를 대비하여, depth estimation algorithm을 적용한다.
- a structure-guided text-to-video model
8. Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance
https://arxiv.org/pdf/2306.00943
-
text와 motion structure(depth)를 사용하여 비디오를 생성한다.

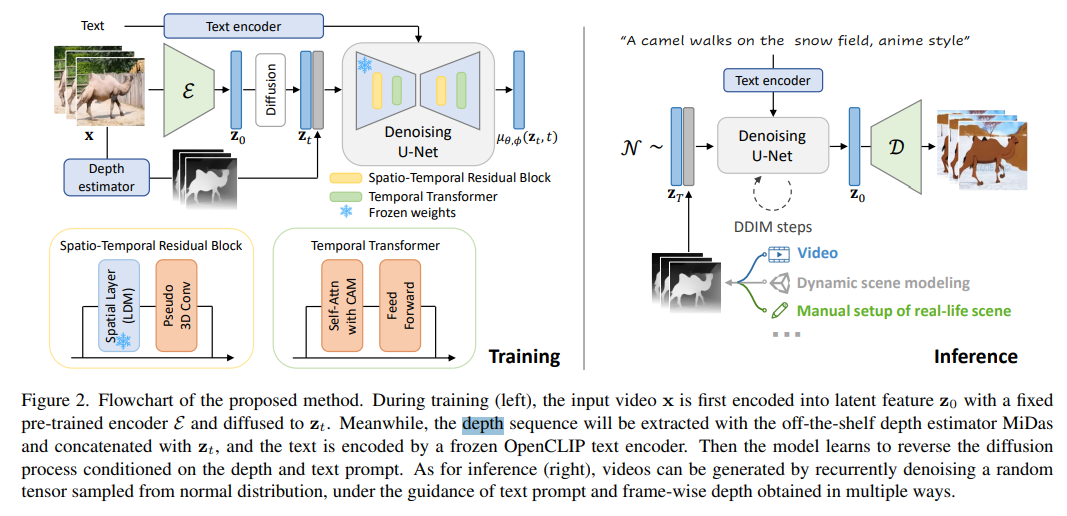
- Training (depth 부분만 설명)
- off-the-shelf depth estimator MiDas 모델을 사용하여, 입력 비디오에서 the depth sequence를 추출한다.
- depth와 text를 기반으로 reverse를 학습한다.
- Training (depth 부분만 설명)
9. VideoComposer
https://arxiv.org/pdf/2306.02018
- 비디오 생성할 때, 텍스트 뿐만 아니라 sketches, depths등 다양한 타입을 조건으로 부여하였다.
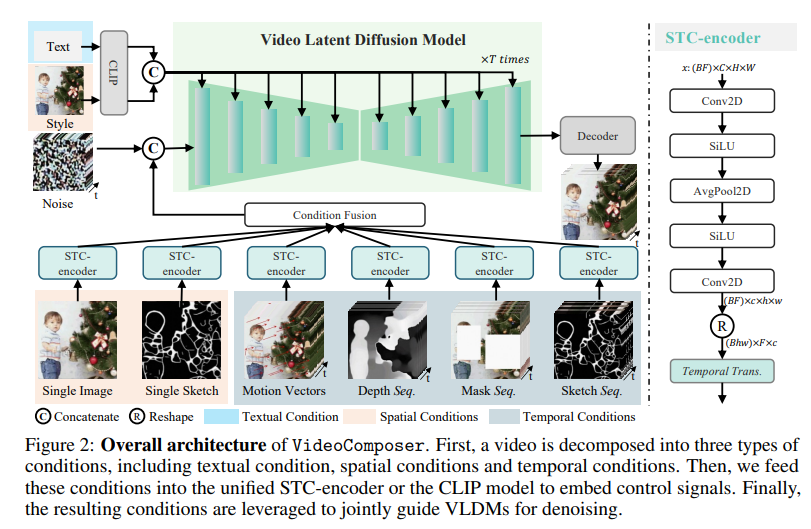
- 과정
- 비디오는 세 개의 타입의 조건들로 분해된다. (1. textual condition, 2. spatial conditions, 3. temporal conditions)
- 위 세 가지 조건들을 unified STC-encoder or the CLIP model에 넣어 임베딩하고 VLDMs를 denoising한다.
10, 11, 12 논문들은 공통적으로 ControlNet을 적용한 사례이다.
10. Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models
https://arxiv.org/pdf/2305.13840
-
이 논문도 위의 논문들과 마찬가지로 depths, canny edge, hed edge등 다양한 조건들을 적용하여 텍스트에서 비디오를 생성한다.

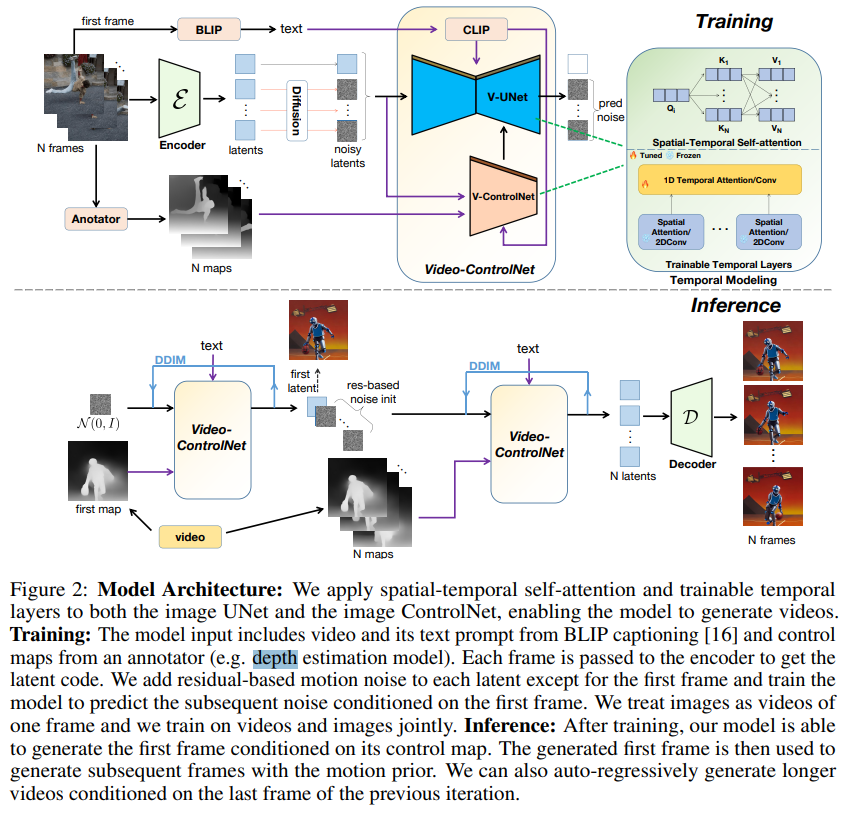
11. ControlVideo: Training-free Controllable Text-to-Video Generation
https://arxiv.org/pdf/2305.13077.pdf
-
위의 모델과 마찬가지로 depth와 edge maps를 조건으로 추가하였다.


12. VideoControlNet: A Motion-Guided Video-to-Video Translation Framework by Using Diffusion Model with ControlNet
https://arxiv.org/pdf/2307.14073.pdf
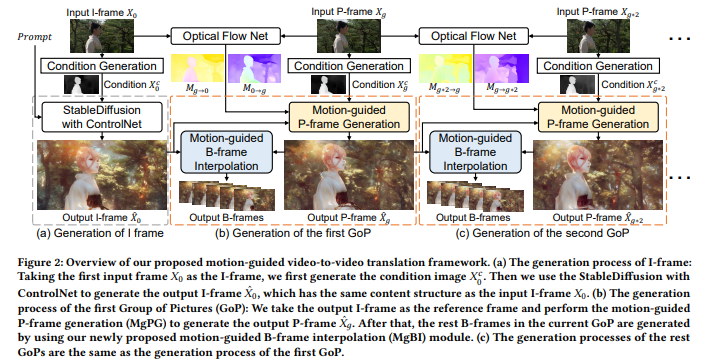
13. Scenescape: Text-driven consistent scene generation
https://arxiv.org/pdf/2302.01133

- pre-trained text-to-image 모델과 geometric prior를 결합하여 비디오를 생성한다.
- ⇒ geometric prior는 pre-trained monocular depth prediction model를 통해 얻는다.
- temporal consistency보다는 spacial-consistency에 주력한 것 같다.

댓글남기기