
[논문 조사] Audio 2개를 mixing하거나, 이어붙이거나, 중첩시켜서 input으로 사용하는 생성모델 논문 조사
아래와 같이 세 가지 모델들을 찾아봤는데, 여러 오디오가 중첩된 비디오에서 오디오를 분리하는 과정(Audio separation)의 역과정에 대한 논문, 즉, Audio separation의 역과정인 분리된 오디오로 여러 오디오가 중첩된 비디오로 생성하는 모델은 현재까지 찾아본 바로는 아직 없는 것 같다.
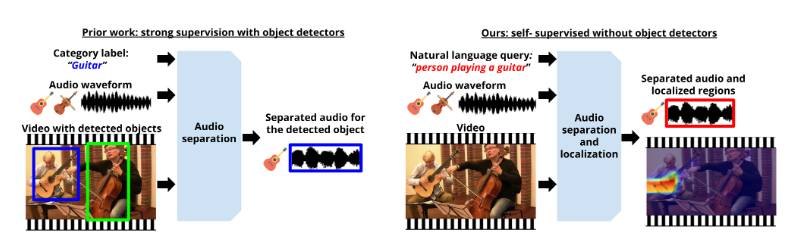
VAST: Video-Audio Separation through Text
1. Music Mixing Style Transfer: A Contrastive Learning Approach to Disentangle Audio Effects
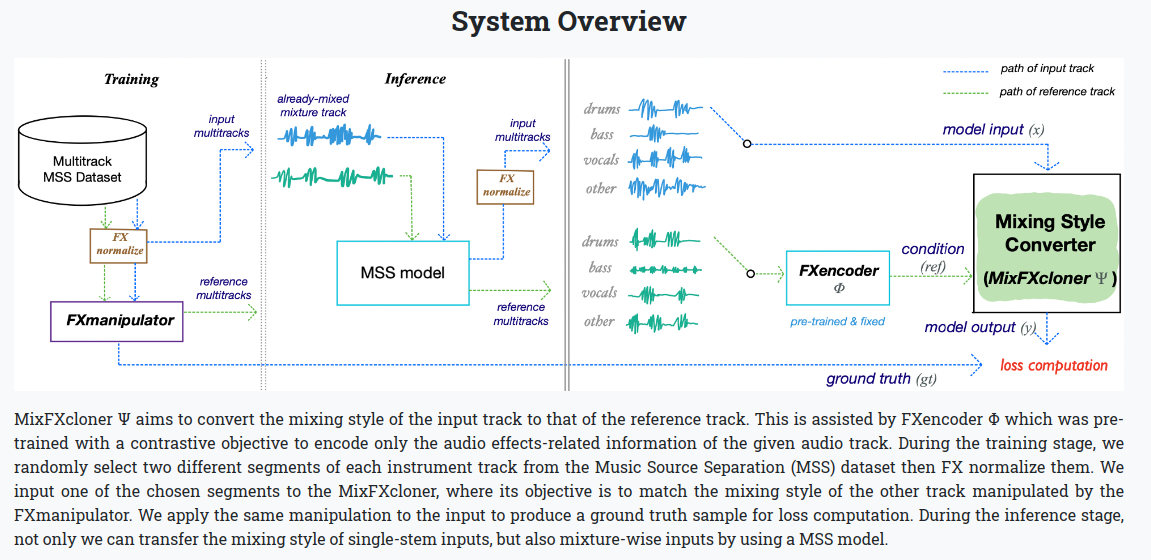
- 여러 오디오 트랙을 입력 받고, 스타일이 변형된 오디오를 생성해주는 구조이다.
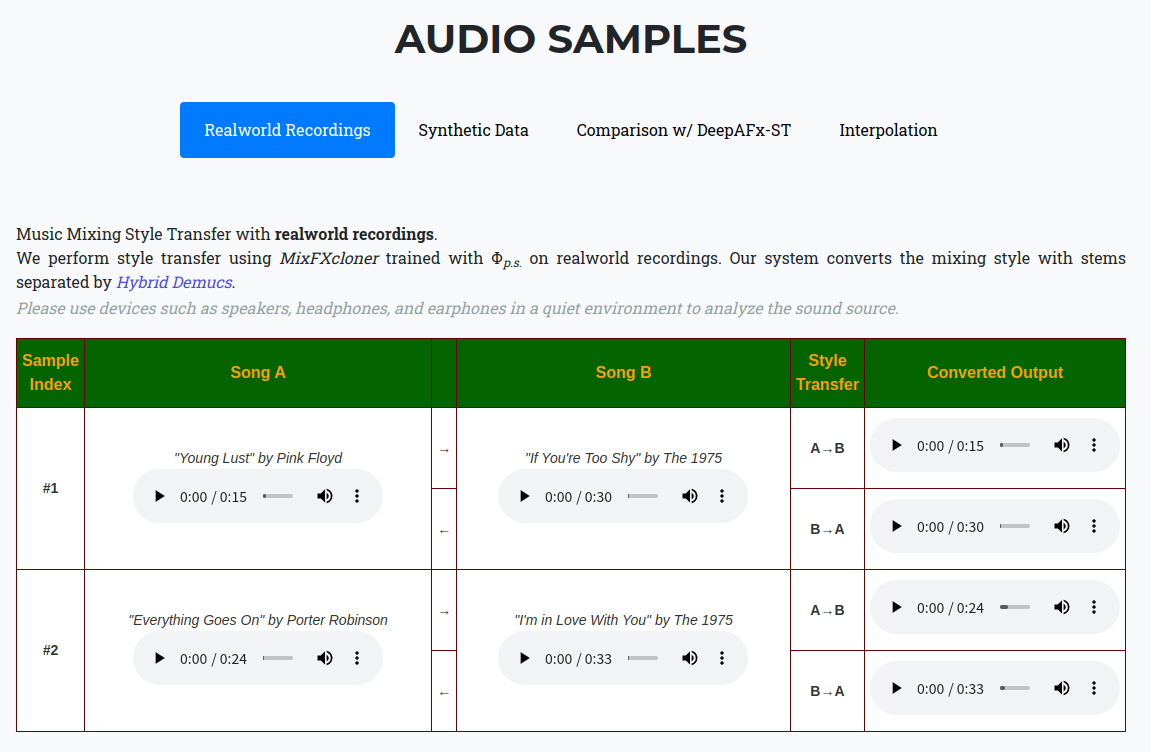
- 아래 링크의 AUDIO SAMPLES를 통해 합성 결과를 확인할 수 있다.
MUSIC MIXING STYLE TRANSFER: https://jhtonykoo.github.io/MixingStyleTransfer/
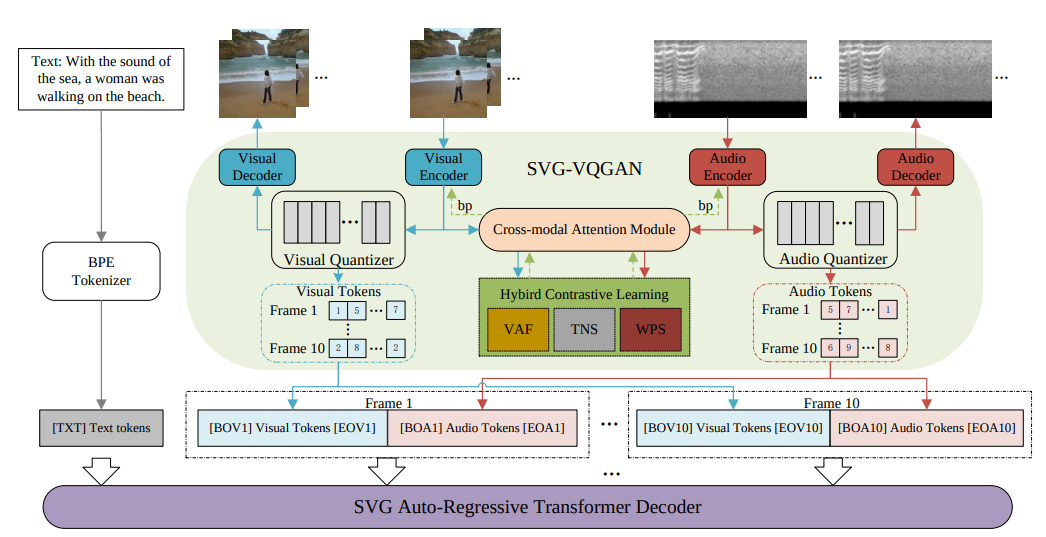
2. Sounding Video Generator: A Unified Framework for Text-guided Sounding Video Generation
-
텍스트를 입력 받았을 때, 사운드와 함께 비디오를 생성해주는 모델이다.
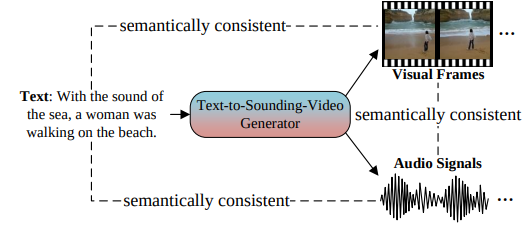
-
찾고자 하는 두 가지의 오디오를 합치는 부분은 없지만, 오디오와 비디오를 함께 생성해주는 부분이 하고자하는 프로젝트와 유사하여 가지고 왔다.
-
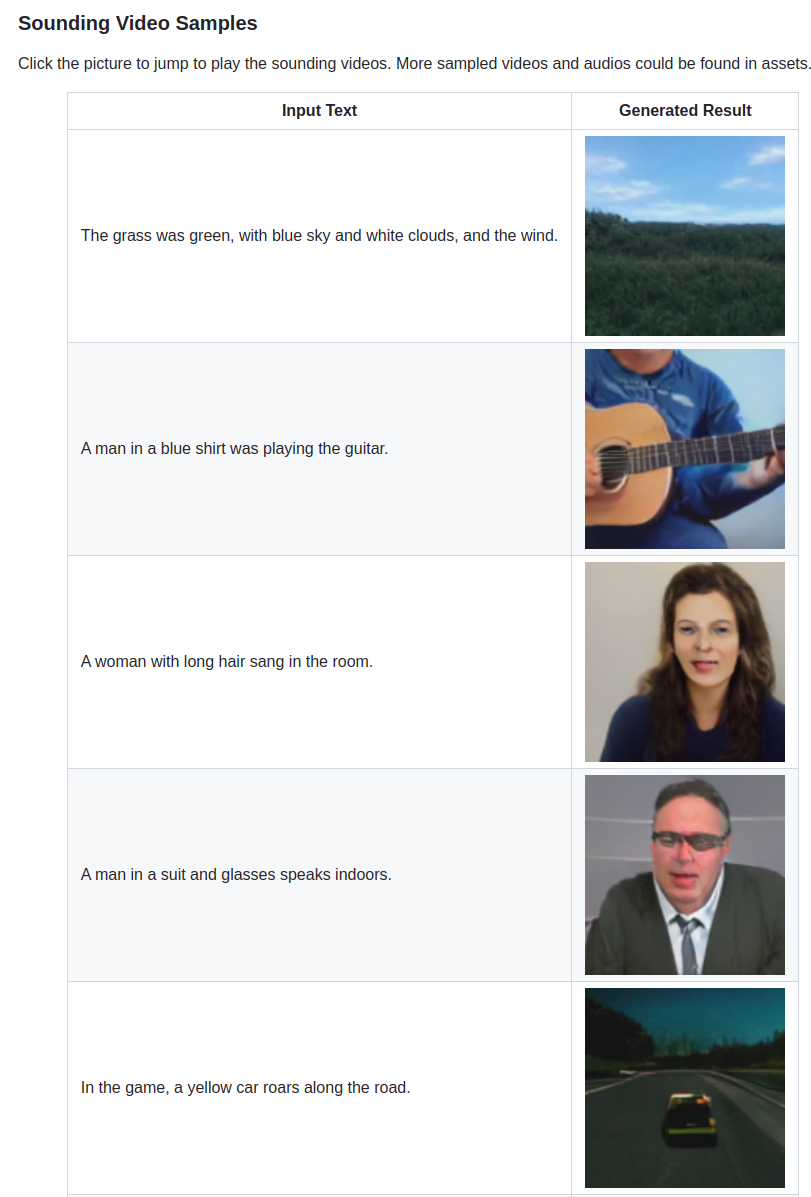
아래 링크의 Sounding Video Samples 부분을 통해 Sample를 확인할 수 있다.
https://github.com/jwliu-cc/svg
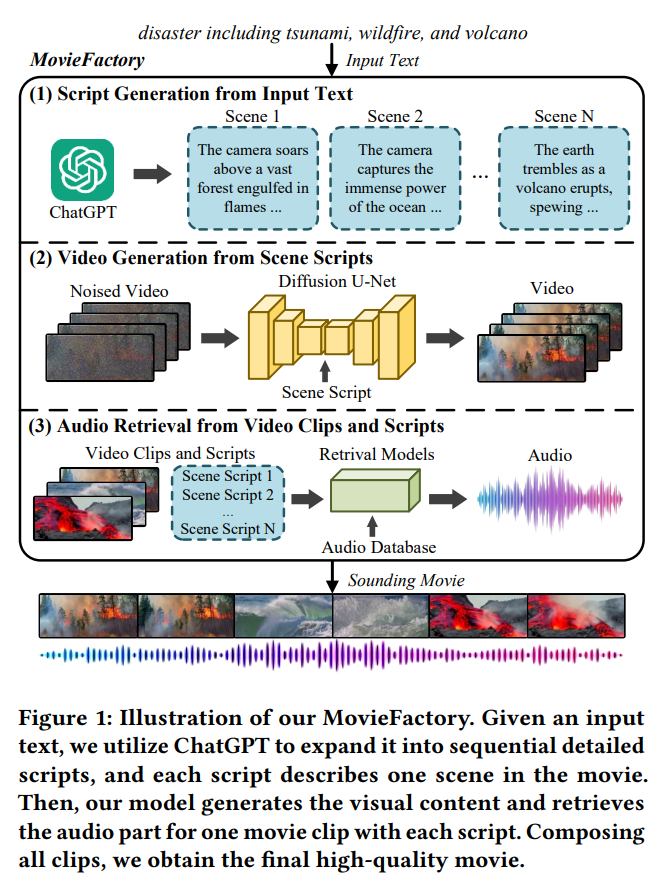
3. MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
- 이 모델은 텍스트를 입력 받았을 때, cinematic-picture (3072×1280), film-style (multi-scene), and multi-modality (sounding) movies를 생성해주는 모델이다.
- 즉, 텍스트를 입력 받았을 때, 영화를 생성해주는 모델이다.
-
직접적으로 여러 오디오가 합쳐진 데이터를 입력 받지는 않지만, 아래 그림과 같이 텍스트 스크립트를 기반으로 비디오를 생성하고, 비디오 클립에 해당하는 오디오 부분을 검색(retrieve)를 통해 가져온다.
- 샘플 영상은 아래 링크를 통해 확인할 수 있다.
https://www.youtube.com/watch?v=tvDknhMFhzk
4. 기타: 오디오-비디오 관련 연구를 리뷰한 논문
Learning in Audio-visual Context: A Review, Analysis, and New Perspective
https://arxiv.org/pdf/2208.09579.pdf
- 오디오-비디오 관련 연구를 크게 3가지로 나누어 분석한 논문이다.
- Audio-visual Boosting
- Cross-modal Perception
- Audio-visual Collaboration
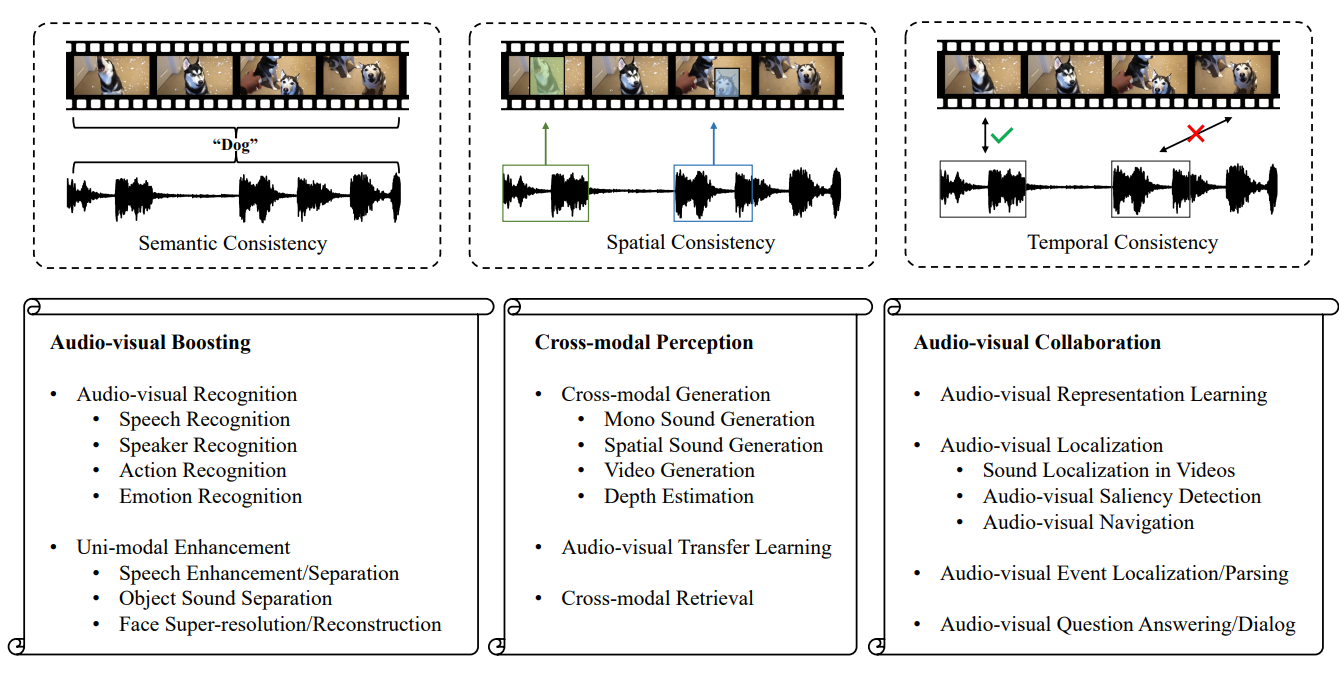
- Audio-visual Boosting (Semantic Consistency)
-
Audio-Visual Recognition
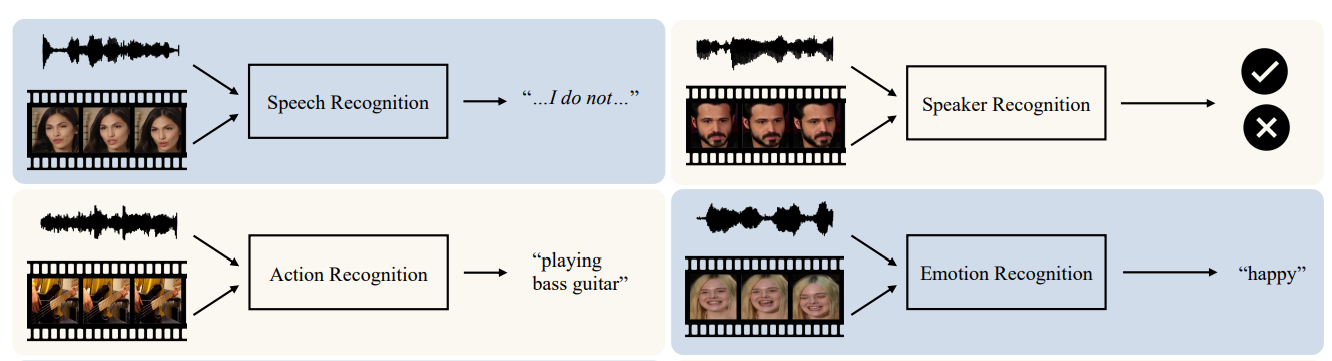
- Speech Recognition
- Speaker Recognition
- Action Recognition
- Emotion Recognition
-
Uni-modal Enhancement
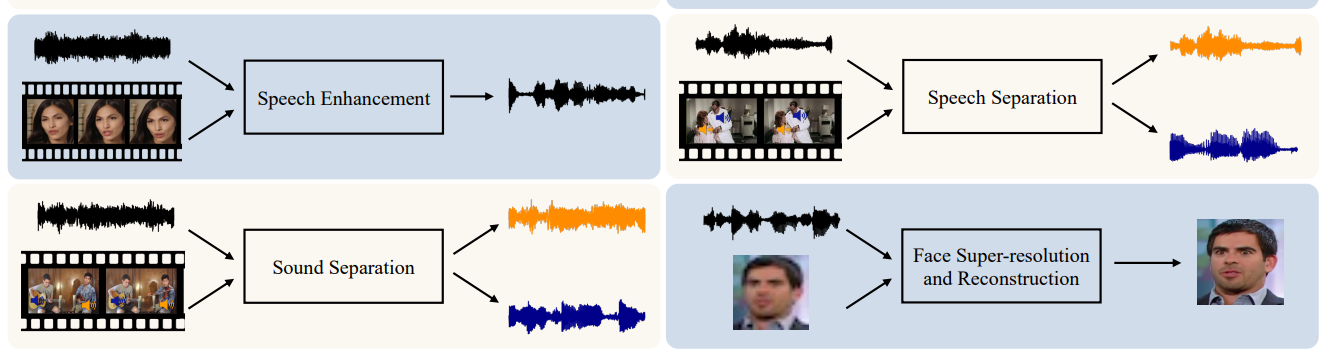
- Speech Enhancement
- Speech Separation
- Sound Separation
- Face Super-resolution and Reconstruction
-
- Cross-modal Perception (Spatial Consistency)
-
Cross-modal Generation
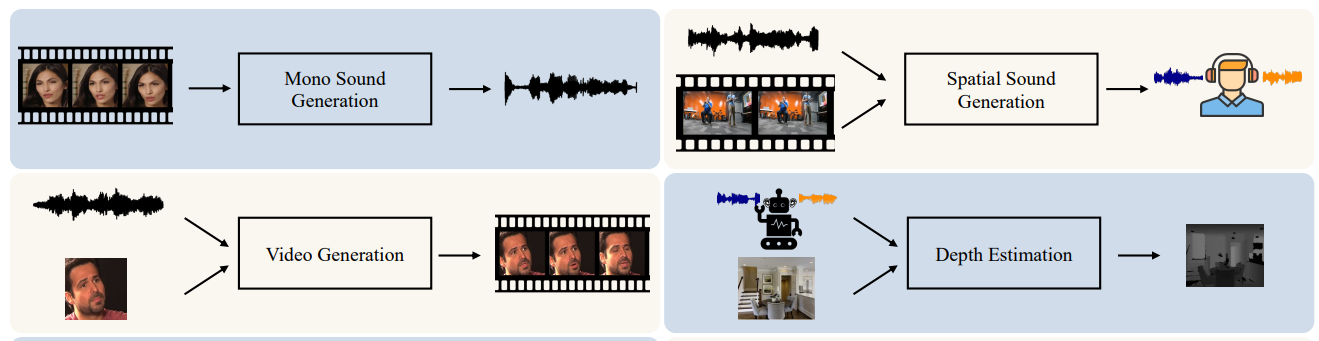
- Mono Sound Generation
- Spatial Sound Generation
- Video Generation
- Depth Estimation
-
Audio-visual Transfer Learning

-
Cross-modal Retrieval
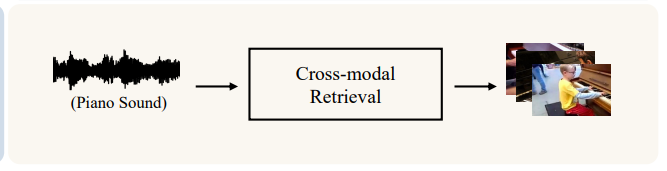
-
- Audio-visual Collaboration (Temporal Consistency)
-
Audio-visual Representation Learning
-
Audio-visual Localization
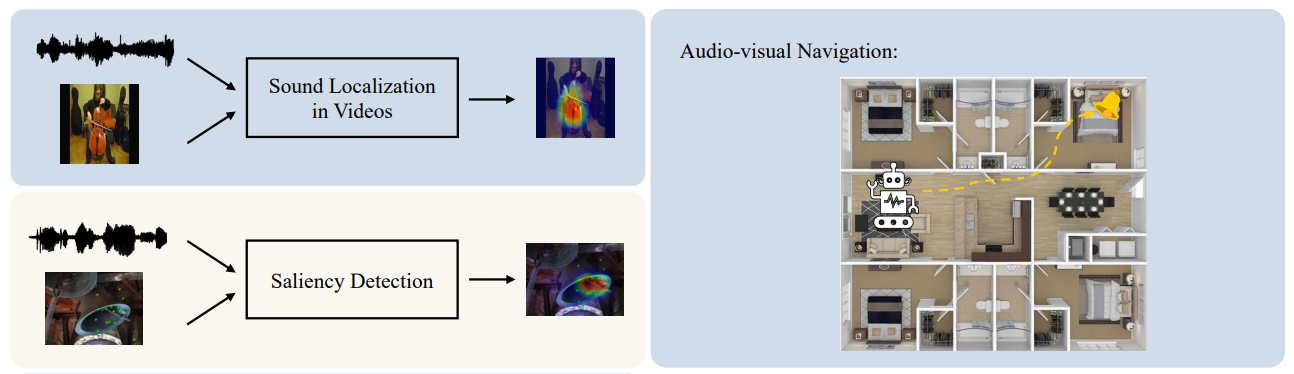
- Sound Localization in Videos
- Saliency Detection
- Audio-visual Navigation
-
Audio-visual Event Localization and Parsing
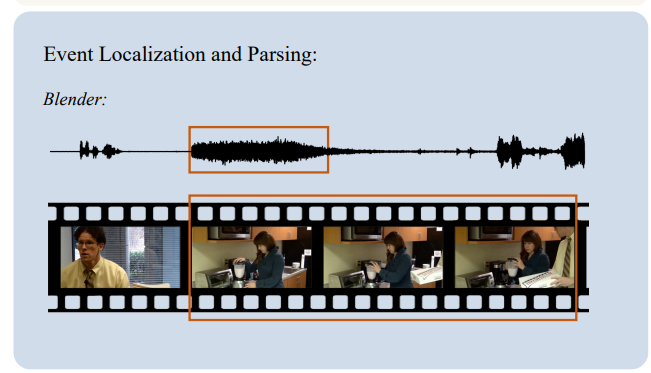
-
Audio-visual Question Answering and Dialog
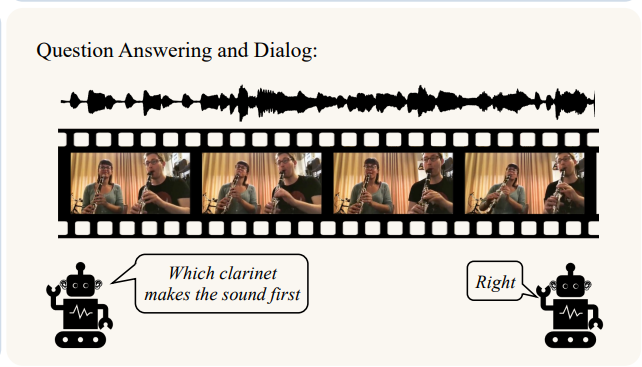
-
댓글남기기