
[논문 리뷰] MM-Diffusion: Learning Multi-Modal Diffusion Models for joint Audio and Video Generation
오늘은 비디오를 생성하는 분야 중 하나인 MM diffusion에 대해서 정리하려고 한다.
MM diffusion은 오디오와 비디오를 동시에 생성하는 모델이다.
오디오와 비디오를 어떻게 alignment하여 함께 생성하는지 원리를 알아보자.
1. Abstract
이 논문에서는 비디오와 오디오를 동시에 생성하는 프레임워크 MM-Diffusion을 제안한다.
1.1. 방법
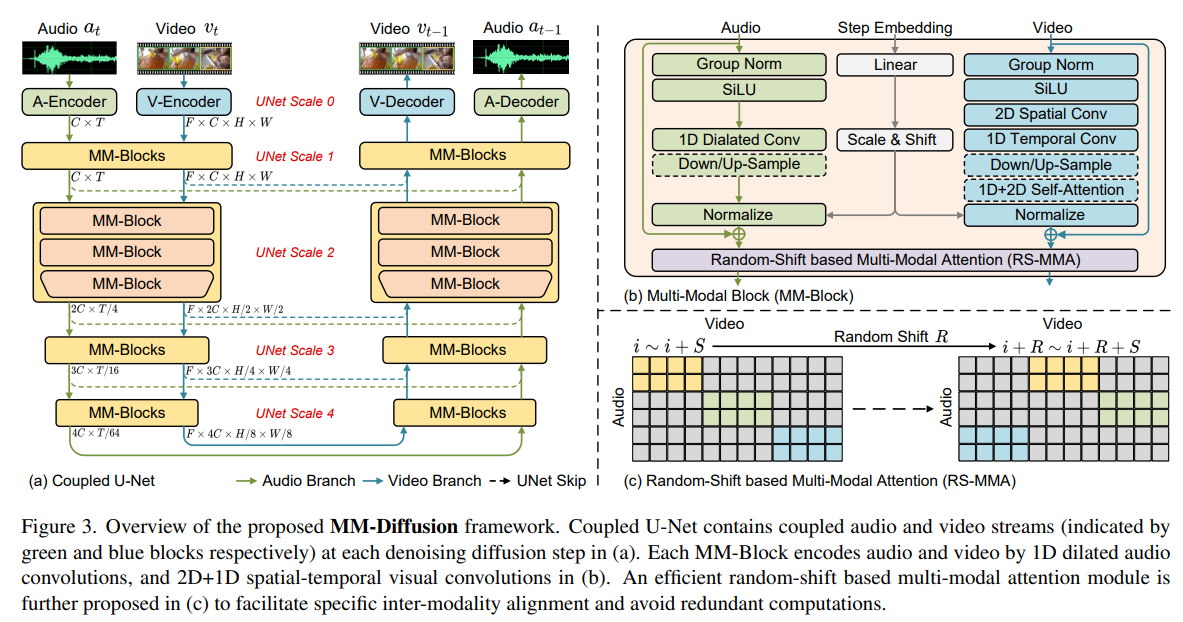
- (a) MM-Diffusion은 Multi-Modal Diffusion (MM-Blocks)과 2개의 denosing autoencoders으로 구성되었다.
- Multi-Modal Diffusion 모델은 sequential multi-model U-Net으로 구성되어, 함께 Denoising 과정을 거친다.
- (b) MM Block: 오디오와 비디오를 아래와 같이 인코딩 한다.
- 오디오는 1D Dialated Conv으로 인코딩되고,
- 비디오는 2D+1D spatial-temporal visual convolutions으로 인코딩된다.
- (c) Random-Shift based Multi-Modal Attention
- 목적: 오디오와 비디오의 두 network를 연결하고, 반복 계산을 피하기 위해서 Multi-Modal Attention 기반 Random-Shift를 도입하였다.
1.2. 결과
- 이후의 더 나아간 experiment에서는 unconditional audio-video 생성과 zero-shot conditional task에서의 우수한 결과를 보여준다.
- FVD와 FAD(풍경 데이터셋), AIST++(dancing 데이터셋)에서 최고의 성능을 냈다.
2. Introduction
기존 연구에서는 오디오와 비디오(시각, 청각)를 결합한 생성 모델이 존재하지 않는다.
따라서 논문에서 하고자하는 것은 audio-video generation 모델을 만드는 것이다.
2.1. Problem
- 비디오와 오디오의 패턴이 다르다. 어떻게 이 둘을 병렬로 합쳐서 하나의 diffusion 모델로 처리할 것인가?
- 비디오 ⇒ 3D (hight, width, RGB, temporal)
- 오디오 ⇒ 1D (waveform digits)
- 비디오와 오디오는 temporal 차원에서 동시에 발생한다. 어떻게 모델이 비디오와 오디오의 관련성을 이해하여 서로에게 영향을 미칠 수 있도록 할 것인가?
2.2. Solution
- Multi-Modal Diffusion Model 제안
- 두 개로 결합된 denosing UNet로 구성되었다.
- 각각 비디오와 오디오를 denosing한다.
- 의미적인 동시성을 학습하기 위해, 새로운 cross-modal attention block를 제시한다.
- ⇒ 비디오와 오디오의 각 순간들을 연관지을 수 있다.
- 방법
- 비디오 프레임과 오디오 랜덤 조각들의 cross-attention을 수행한다.
- 이 방식은 temporal redundancies를 줄여주어, 모달간의 상호작용을 효율적으로 할 수 있도록 한다.
- 두 개로 결합된 denosing UNet로 구성되었다.
3. Related Work
3.1. Diffusion Probability Models (DPMs)
3.1.1. DPM
- forward process와 reverse process로 구성
- 미분 방정식을 통해 두 process를 증명할 수 있다.
- a reweighted objective으로 더 좋은 성능을 낸다.
- 수백번의 denosing 과정을 반복해서 거치기 때문에 다른 생성모델에 비해 생성 속도가 느리다.
3.1.2. Denosing Diffusion Implicit Model (DDIM)
- DPM의 속도를 증가시킨 모델이다.
- 10~20개 정도의 Time Step만 사용한다.
3.2. Cross-Modality Generation
- Audio-to-Visual generation
- ex) Sound2Sight
- 처음으로 비디오와 오디오 align 제안하였다.
- TATS
- audio latent embedding을 video embedding에 투영하는 Time-Sensitive Transformer 제안하였다.
- ex) Sound2Sight
- Visual-to-Audio generation
- CMT
- 비디오에 맞는 배경 음악을 제시하는 모델이다.
- CDCD
- contrastive diffusion loss 제안하였다. ⇒ 비디오를 기반으로 생성된 오디오를 일치시키는 Task의 성능을 향상시켰다.
- CMT
- Bidirectional conditional generation
- audio-to-image와 image-to-audio 프레임워크를 제안하였다.
- CMCGAN
- audio-image의 양방향 변환을 하나의 통합된 프레임워크로 결합시켰다.
3.3. 기존 연구의 한계
- 한번에 하나의 모달리티만 생성하는 한계가 있다.
- 본 논문에서는 두 모달리티를 동시에 생성하려고 한다.
4. Approach
4.1. Preliminaries of Vanilla Diffusion
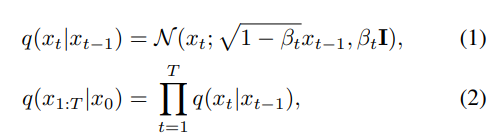
- $t ∈ [1, T]$,
- $β_0, β_1, …, β_T$: 사전에 정의된 schedule 변수 ⇒ 이 논문에서는 linear noise schedule 사용한다.
- 원본 이미지로 복원하기 위해서, forward process를 reverse하는 과정을 학습한다.
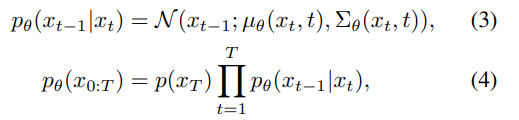
- ⇒ 모델 $\theta$ 를 학습하여 $p_\theta(x_{t-1}|x_t)$ 를 구하는데 이는 $q(x_{t-1}|x_t, x_0)$ 을 근사화한 것이다.
- 우리는 (3) $p_\theta(x_{t-1}|x_t)$ 의 매 시점 평균과 분산을 구해야한다. (논문에서 분산 예측은 제거. 성능 향상이 조금밖에 이뤄지지 않기 때문)
- (4)은 $p(x_T)$의 상태에서 디노이징하는 상태를 곱해서 $p(x_0)$의 상태로 만드는 수식이다.
4.2. Multi-Modal Diffusion Models
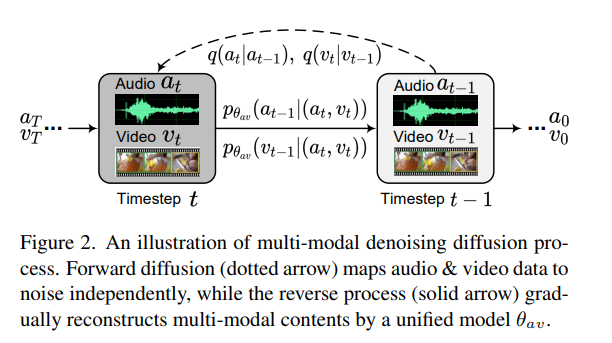
- 3.1에서 다룬 vanilla diffusion은 single modality 생성한다. 이 논문의 목적은 2개의 일치하는 modalities를 복원(생성)하는 것이다.
- 오디오와 비디오의 시점이 $a_t$, $v_t$로 각각 주어졌을 때, 오디오 $a_{t-1}$의 분포와 $v_{t-1}$의 분포를 알아보자.
- paired data $(a, v)$의 $a$와 $v$는 다른 분포를 가졌기에 독립이다.
- $q(a_{t−1}|a_t, a_0)$ 와 $q(v_{t−1}|v_t, v_0)$ 를 각각 바로 fitting하지 않고, unified model $\theta_{av}$ 로 합쳐서 하나의 디퓨전 프로세스를 만들어 fitting한다.
-
즉, $a$와 $v$의 결합분포 $p_θ{_{av}}(a_{t−1}|(a_t, v_t))$ 를 예측하는 것이다.
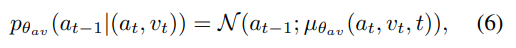
- 위 수식은 A = $a_t$와 V = $v_t$가 주어졌을 때, $a_{t-1}$의 확률 분포이다.
- Loss
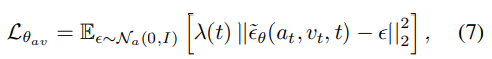
- $t ∈ [0, T]$ 이고, $λ_t$ 는 optional 하게 가중치를 부여하는 함수이다.
4.3. Coupled U-Net for Joint Audio-Video Denoising (비디오-오다오 관계성 학습)
- Single modality 생성에 U-Net이 효과가 있음을 여러 논문에서 증명되었다.
- 이 논문에서는 coupled U-Net을 제안한다.
- 2개의 single modal U-Net으로 구성되었다.
- input audio와 video를 텐서 쌍으로 공식화한다. $(a, v) ∈ (A, V)$
- a의 shape은 (C X T)로, C는 채널 수, T는 temporal dimension이다.
- v의 shape은 (F X C X H X W)로, F은 frame number, C는 채널 수, H는 height, W는 witdth dimension이다.
4.3.1. Efficient Multi-Modal Blocks.
- Video encoder
- 3D가 아닌 1D convolution을 쌓고, 그 다음 2D convolution을 쌓는다.
- Video Attention modules도 2D와 1D attention으로 구성되었다.
- Audio
- 원본의 1D convolution이 아닌, 확장된(dilated) convolution layer를 쌓는다.
- 확장정도는 $1$에서 $2^N$배가 되며, N은 하이퍼파라미터로 직접 지정한다.
- 모든 temporal attention들을 제거했다.
- 계산량이 많고, 큰 효과를 얻지 못하기 때문이다. (이전 실험에서 증명됨)
- 원본의 1D convolution이 아닌, 확장된(dilated) convolution layer를 쌓는다.
4.3.2. Random-Shift based Multi-Modal Attention
- Video block과 Audio block을 연결하기 위해서 공동으로 alignment를 학습한다.
- ⇒ cross-attention 수행 (논문에서 가장 쉽고 단순한 방법이랬다)
- Cross-Attention
- Video와 Audio의 original attention map은 복잡도가 매우 크다 ⇒ $O((F \times H \times W)\times T)$
- 또한 비디오와 오디오는 모두 temporal redundant를 가지고 있다. 인접한 프레임들은 많은 부분이 유사한 정보를 담고 있다. ⇒ 따라서 압축 등의 방법으로 효율적으로 처리가 가능하다.
- 따라서 모든 부분에서 cross-attention을 하는 것이 아니라 특정 부분만 하면 된다.
- Random-Shift
- random-shift를 적용하여 Multi-Modal Attention을 수행하여 Video와 Audio를 Align한다.
- k번째 결합된 U-Nets layer의 output, input shape
- output shape ⇒ (H, W, C, T)
- input
- Video input shape ⇒ (F, H, W)
- Audio input shape ⇒ (C, T)
- video frame과 audio signal 을 align하는 과정
- audio stream을 비디오 프레임에 맞춰 segments로 나눈다. ⇒ {$a_1, a_2, …, a_F$}
- 각 a1 segment의 shape ⇒ (C, T/F)
- 윈도우 사이즈 S와 ramdom-shift number R ∈ [0, F-S] 를 설정한다.
- audio segment $a_i$와 video segment $v_j$ 간의 attention weight을 계산한다.
- $f_{start} = (i + R)\%F$
- $f_{end} = (i+R+S)\%F$
- audio segment $a_i$와 video segment $v_j$ 간의 attention weight을 계산한다.
- 오디오 segment a_i와 sampled된 video segment v_j의 Cross attention을 수행한다.
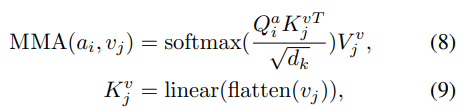
- 장점1. 계산 복잡도가 줄어들었다
- ⇒ $O((S × H × W) × (S × T/F))$
- 모든 프레임에 대해서 계산하는 것이 아닌 프레임보다 큰 단위인 S를 적용한다.
- ⇒ $O((S × H × W) × (S × T/F))$
- 장점2. 현재 시점의 입력을 처리하면서도 중요한 시간적인 정보를 유지하고 활용할 수 있다.
- 장점1. 계산 복잡도가 줄어들었다
- audio stream을 비디오 프레임에 맞춰 segments로 나눈다. ⇒ {$a_1, a_2, …, a_F$}
4.4. Zero-Shot Transfer to Conditional Generation
- 위 논문에서는 두 방식의 conditional generation을 언급하였고, improved gradient guided method를 사용하였다.
- Replacement-based method
- 비디오를 기반으로 오디오를 생성하는 방식이다.(video-to-audio) ⇒ $a \sim p_\theta{_{av}}(a|v)$
- $p_θ{{av}}(a_t|(a{t+1}, v_{t+1}))$ 에서 나온 v를 ⇒ diffusion step $q(\hat{v}_{t+1}|v)$ 에서 추출한 샘플로 변경한다.
- ⇒ target $a_t \sim E_q(a_t|(a_{t+1}, \hat{v}_{t+1}))$
- ⇒ 단점: original v는 무시된다.
- ⇒ target $a_t \sim E_q(a_t|(a_{t+1}, \hat{v}_{t+1}))$
- $p_θ{{av}}(a_t|(a{t+1}, v_{t+1}))$ 에서 나온 v를 ⇒ diffusion step $q(\hat{v}_{t+1}|v)$ 에서 추출한 샘플로 변경한다.
- 비디오를 기반으로 오디오를 생성하는 방식이다.(video-to-audio) ⇒ $a \sim p_\theta{_{av}}(a|v)$
-
improved gradient guided method
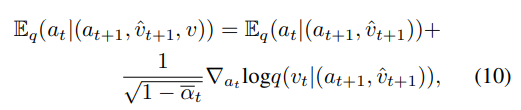
-
original v를 고려하고자한다.
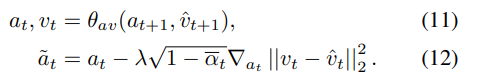
- $\tilde{a}_t$는 reverse process에서 구한 $a_t$ 와 $v_t$ , 그리고 $v_{t-1}$ 에서 forward process에서 구한 $\hat{v}_t$ 를 기반으로 생성된 오디오다.
- $\lambda$ 는 gradient weight 역할을 하여, conditioning 강도를 조절한다.
-
기존의 conditional generation 모델과의 차이점
- 기존: condition data에 대해서 학습을 시켜야한다. (condition을 변경할 필요 없음)
- 논문: condition data에 대해서 학습 필요 없다. (reverse process를 함께 거치므로 조건이 process 거칠 때마다 변경됨)
-
- Replacement-based method
5. Experiments
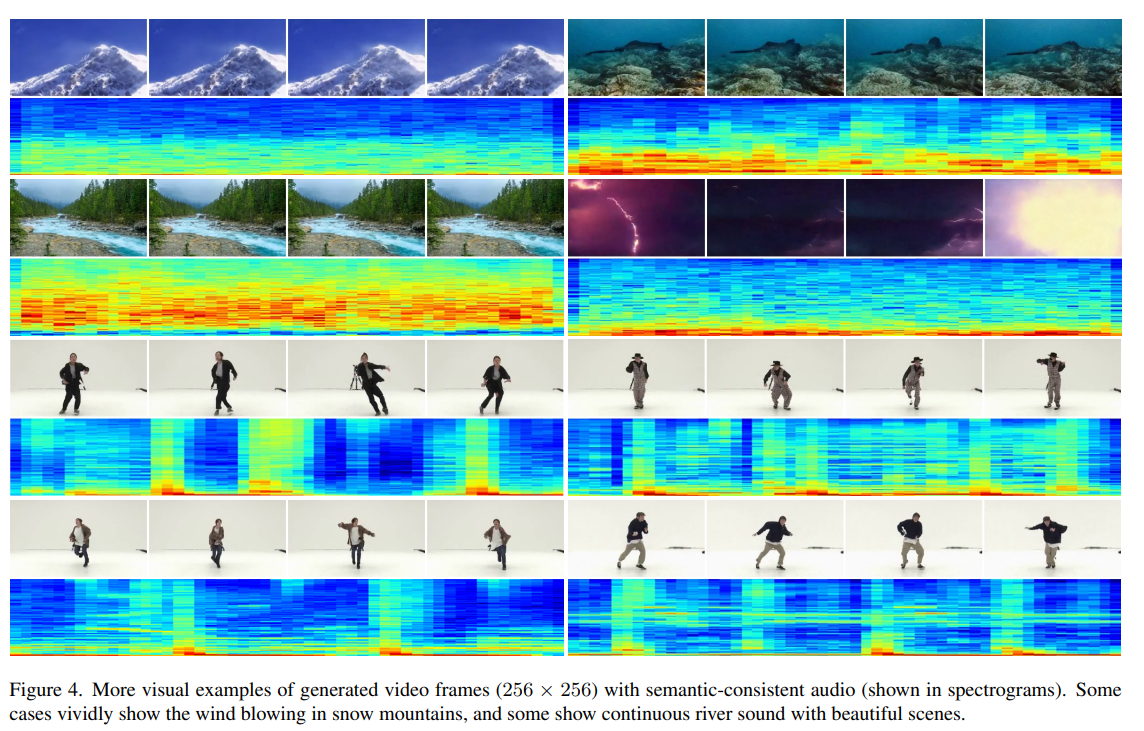
5.1. Implementation Details
5.1.1. Diffusion model
- linear noise schedule
- step T = 1000
- DPM-Solver 적용 ⇒ sampling 속도 상승!
5.1.2. Model architecture
- Coupled U-Net
- 비디오 생성: 16 x 3 x 64 x 64
- 오디오 생성: 1 x 25,600
- 고해상도모델은 64 ⇒ 256으로 설정
5.2. Evaluation Metrics
5.2.1 Objective Evaluation
- 비디오 생성
- Frechet video distance (FVD)
- 실제 비디오와 생성된 비디오 분포 간의 차이를 측정하여 생성된 비디오의 품질을 평가하는 척도이다.
- 낮을 수록 좋다.
- kernel video distance (KVD)
- 낮을 수록 좋다.
- Frechet video distance (FVD)
- 오디오 생성
- Frechet audio distance (FAD)
- 생성된 오디오와 실제 오디오 간의 차이를 측정하여 모델의 품질과 정확성을 평가하는 척도이다.
- 낮을 수록 좋다.
- Frechet audio distance (FAD)
- Audio feature 추출기로 AudioCLIP 사용하였다.
5.2.2. Subjective Evaluation
- 생성된 audio와 video의 성능과 관계성 평가한다.
- 다음과 같은 2가지 방식을 사용하였다.
- MOS
- Turing Test
5.3 Objective Comparison with SOTA methods
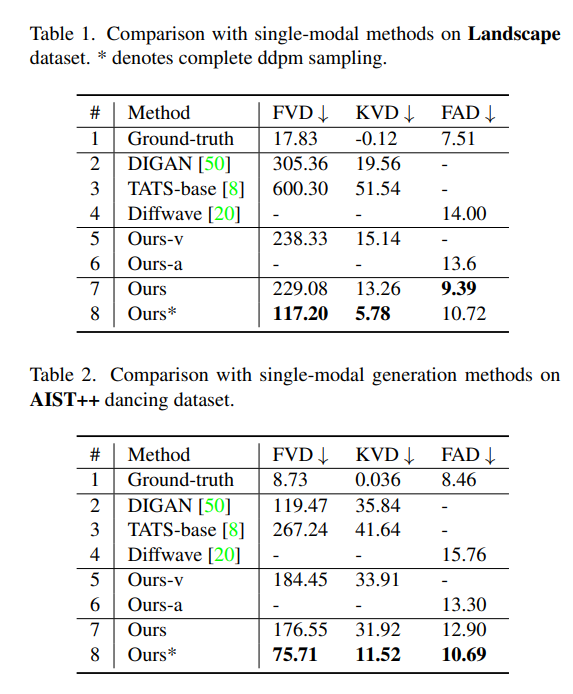
- Quality 비교
- 비디오 생성: SOTA 모델인 DIGAN과 TATS와 비교하였다.
- 오디오 생성: SOTA 모델인 Diffwave와 비교하였다.
- 다른 방법
- 각각을 독립적으로 생성하기 위해 Coupled U-Nets를 오디오 U-Net (Our-a)과 비디오 U-Net (Our-v)으로 분리하여 비교하였다.
- 결론
- 논문에서 제시한 모델은 오디오 생성과 비디오 생성 각각의 분야에서 SOTA의 성능을 넘어섰다.
- 비디오 U-Net (Our-v) 모델로도 SOTA인 DIGAN과 TATS의 성능을 넘어섰다.
5.4. Ablation Studies
5.4.1. Random-Shift based Multi-modal Attention
-
Differnet window sizes
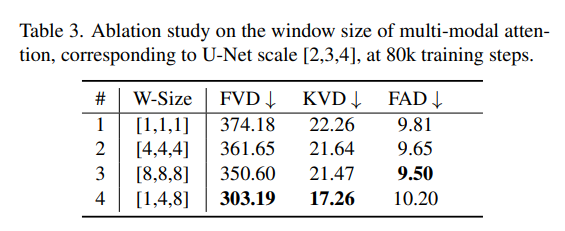
- U-Net scale [2,3,4]에 window size를 각각 다르게해서 측정하였다.
- 첫 3줄: window size가 커질 수록, 더 좋은 성능을 냄을 알 수 있다.
- adaptive window size가 효율적인 구성이라는 것을 나타냈다. 특히 비디오 생성 quality 개선에 효과적임을 알 수 있다.
-
Random Shift mechanism
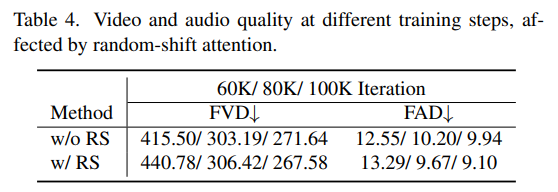
- 오디오 생성 부분에서 Random shift를 적용한 모델이 더 좋은 성능을 보여주고, 수렴 속도가 빠르다.
- 첫 줄: Random shift 적용 안 함
- 둘째 줄: Random shift 적용
- 오디오 생성 부분에서 Random shift를 적용한 모델이 더 좋은 성능을 보여주고, 수렴 속도가 빠르다.
5.4.2. Zero-Shot Conditional Generation
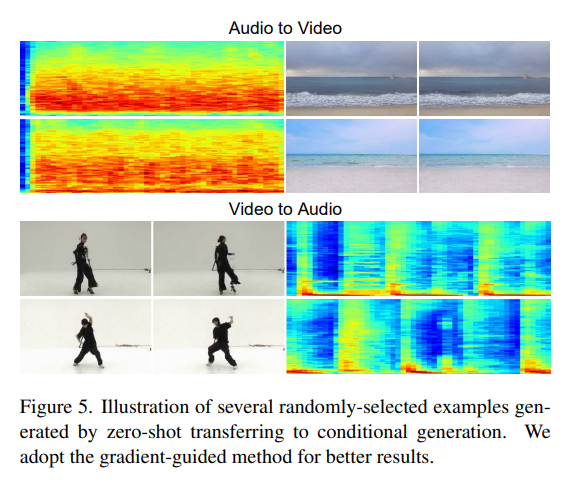
- 비디오 생성 분야에서 gradient-guided method가 replacement method 보다 성능이 좋았다.
- 추가적인 훈련 없이도 modality transfer 가능하다.
5.5. User Studies
5.5.1. Comparison with other Methods
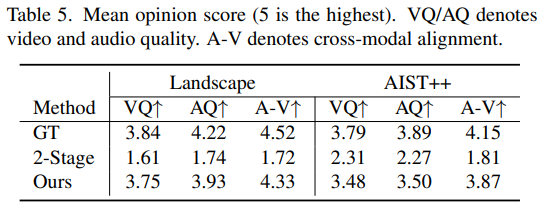
5.5.2. Turing Test
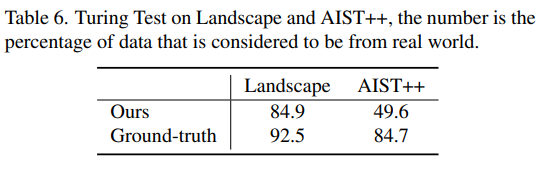
댓글남기기