
[논문 리뷰] First-Person Hand Action Benchmark with RGB-D Videos and 3D Hand Pose Annotations
오늘은 hand recognition을 위해 데이터셋(FPHA)을 제안하는 논문을 읽어볼 것이다.
1. Abstract
이 논문에서는 1인칭 시점에서 물체와 상호작용하는 hand action 인식을 위해 새로운 First-Person Hand Action(FPHA) 데이터셋을 제안하였고, 이를 활용한 18가지의 baseline, SOTA 실험을 통해 Hand action recognition을 구축하고, 평가하였다.
2. Introduction
사람의 body와는 다르게 손은 action recognition을 위한 신뢰할 만한 hand pose 데이터가 없다. 그렇기에 위 논문에서 1인칭 시점의 hand action sequence 데이터셋(FPHA)을 제안하였다.
연구의 contribution은 다음과 같다:
- Dataset: 1인칭 hand-object action, pose 연구를 위한 새로운 데이터셋을 제안한다.
- Action Recognition: 제안된 데이터셋으로 RGB-D, pose-based action recognition의 18가지 baseline과 SOTA를 평가한다.
- Hand pose: 제안된 데이터셋으로 SOTA hand pose estimator를 평가한다.
3. Related work
이전 연구에서는, 손은 경험적 분류법에 따라 low-level로 모델링되었다.
또한 낮은 퀄리티의 hand tracker로 인해 action과 pose label은 정확도가 낮다는 한계가 있다.
이 논문에서는 새로운 데이터셋을 제안하여 이러한 한계점들을 극복하고자 한다.
4. Daily hand-object action dataset
4.1. Dataset overview
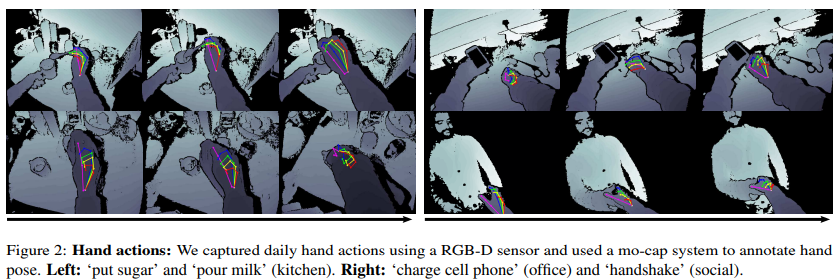
FPHA 데이터셋은 1175개의 action videos로, 45가지의 action과, 3개의 다른 시나리오, 6명의 actor로 구성되었다.
105,459개의 RGB-D frame은 각각 action pose와 action category로 주석을 달았다.
6D object pose, 3D location, mesh model은 4가지의 object와 10가지의 action으로 구성되었다.
4.2. Hand-object actions
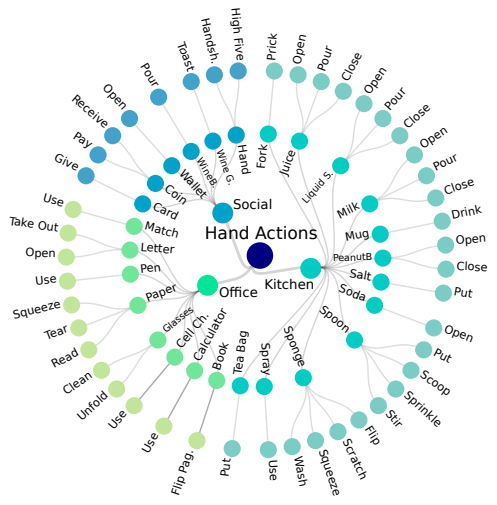
- 위 이미지는 Hand-object actions에 대한 분류 체계를 보여준다.
- 다음과 같이 구성되었다.
- 45가지의 action과, 26가지의 object.
- 각 object는 최소 1개에서 최대 4개의 action을 가진다.
- ex) sponge-wash, sponge-scratch, sponge-squeeze, sponge-filp
- 3가지의 시나리오.
- ex) Kitchen, Office, Social
- 각 hand와 object쌍을 다른 action으로 취급하였다.
4.3. Sensors and data acquisition
4.3.1. Visual data
- Intel RealSense SR300 RGB-D camera 사용하였다.
- 30fps의 프레임 속도로 촬영하였다.
- color 해상도 1920x1080, depth 해상도 640x480으로 설정하였다.
4.3.2. Pose annotation
- actor의 손가락과 손목에 6개의 자석 센서 착용하였다. ⇒ 이를 통해 위치, 방향을 제공한다.
- 전체적인 hand pose는 inverse kinematics를 통해 추정할 수 있다.
- object은 1개 이상의 센서를 object 중앙에 부착한다.
4.3.3. Recording process
- 6명의 actor로 촬영했고, 모두 오른손만 사용하였다.
4.4. Dataset statistics
4.4.1. Taxonomy
- 각 object는 최소 1개에서 최대 4개의 action을 가지도록 하였다.
- hand도 object에 포함된다.
- ex) ‘hand shake’, ‘high five’
4.4.2. Videos per action class
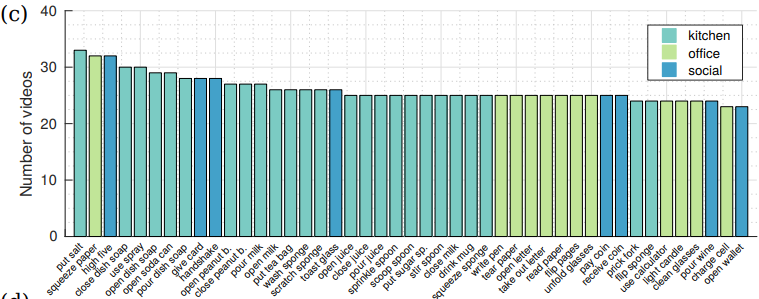
- 평균적으로 action class 하나에 26.11 sequence, object 하나에 45.19 sequence로 구성된다.
4.4.3. Duration of video
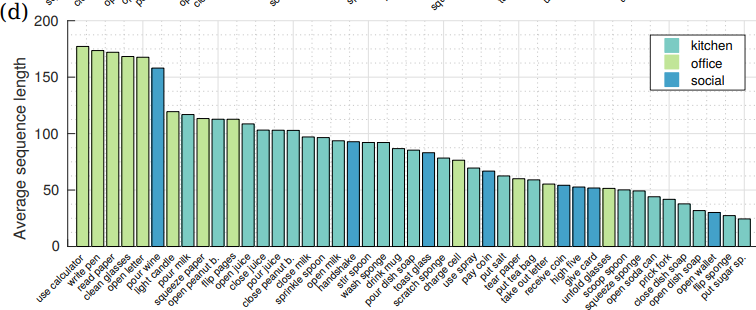
- 위 그래프는 action class에 대한 평균 sequence 길이를 나타낸다.
4.4.4. Grasps
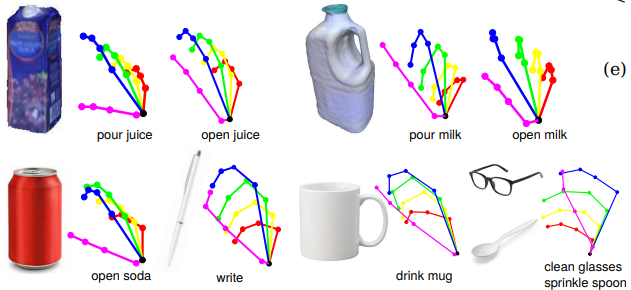
- 34가지의 grasp type 발견하였다.
- 위 그림은 object, hand pose, action의 관계를 나타낸다.
4.4.5. Viewpoints
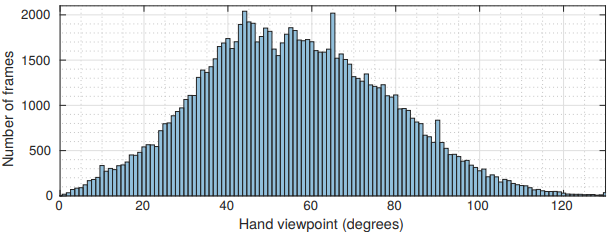
- 위 그래프는 hand viewpoint에 따른 프레임 수를 나타낸다.
- viewpoint는 카메라와 손바닥사이의 각도를 의미한다.
4.4.6. Hand occlusion
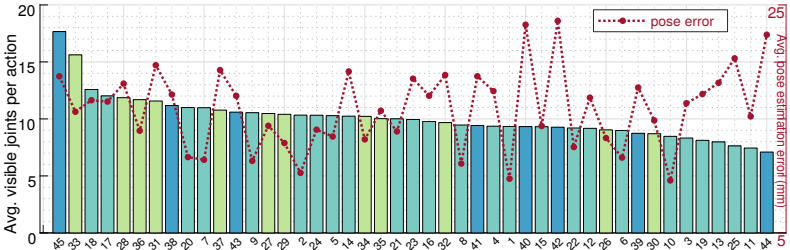
- 막대그래프: action class 하나당 손의 일부가 가려지지 않은(not occluded) joint 수의 평균을 의미한다.
- 꺾은선그래프: action class에 따른 pose error를 나타낸다.
4.4.7. Object pose
- non-rigid object를 표현하기 위해 6D object pose와 mesh model 사용하였다.
4.5. Comparison with other datasets
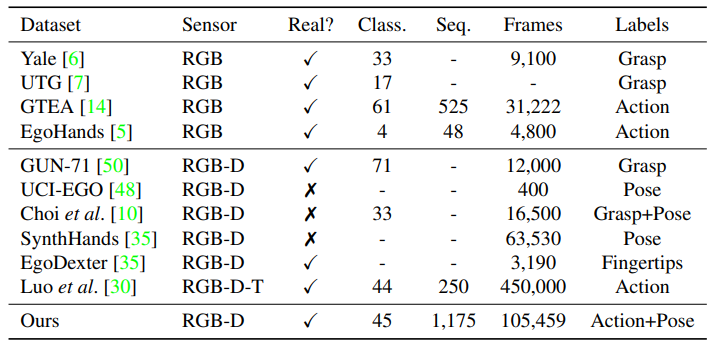
- 위의 표는 일반적으로 사용되는 1인칭 시점의 hand-object 데이터셋을 요약한 것이다.
- 논문에서 제시한 FPHA 데이터셋은 다른 데이터셋에 비해 다양성, 프레임수, real data등에서 좋다는 것을 알 수 있다.
5. Evaluated algorithms and baselines
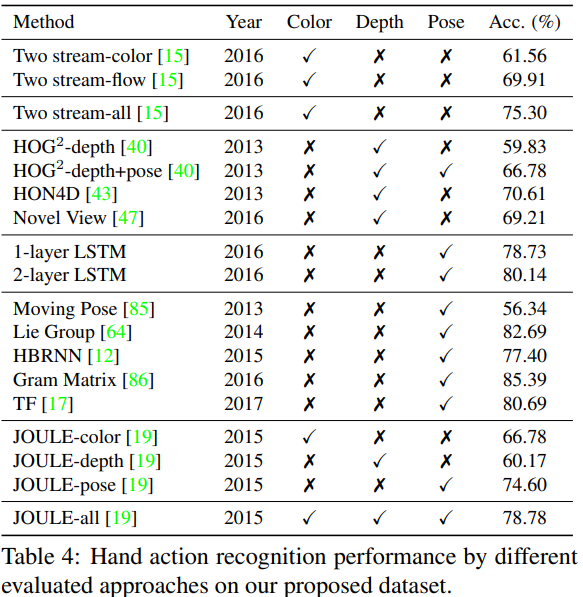
- FPHA 데이터셋으로 Action recognition과 Hand pose 추정에 대한 최근의 SOTA를 평가하기 위해 ConvNet를 사용하였다.
- 최근의 SOTA로는 위의 표와 같은 Method를 사용하였고, Test 정확도 결과는 위의 표와 같다.
- (대부분의 모델은 body action 목적으로 만들어져있어, hand에 맞게 다듬었다.)
6. Benchmark evaluation results
Daily hand-object actions 데이터 세트에서 실행 가능한 알고리즘들의 평가 결과와 비교를 진행하였다.
6.1. Action recognition
6.1.1. A baseline: LSTM
- baseline으로 LSTM model을 사용하였다.
- 특징: do not go deep, unidirectional network
- 뉴런 수를 100으로, dropout을 0.2으로 설정하였다.
- Tensorflow, Adam optimizer를 사용하였다.
Training and test protocols
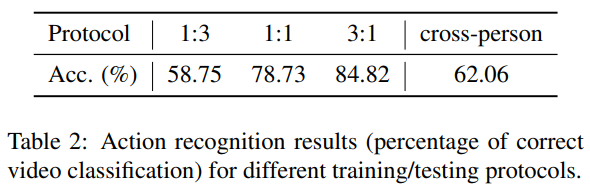
- 3개의 서로 다른 Train과 Test 비율을 사용한다.
- 1:3, 1:1, 3:1
- 6명의 actor를 기준으로 6-fold cross-validation을 진행한다.
- 2번 프로토콜을 사용한 성능이 가장 좋지 못하다. ⇒ 사람간의 action style이 다르기 때문이다.
Results discussion
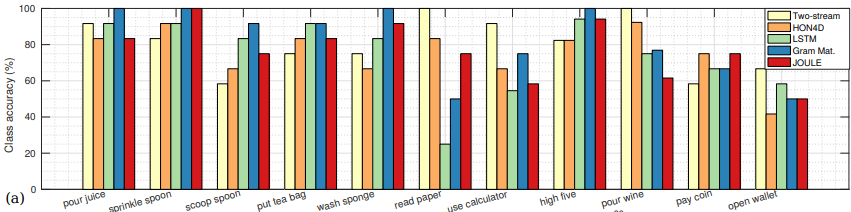
위 그래프는 11개의 action class에 따른 5가지 모델의 정확도 성능을 나타낸다.
-
한 action class에 대해 hand pose가 서로 비슷하지않고, 미묘한 action일 경우에는 낮은 성능이 나왔다.
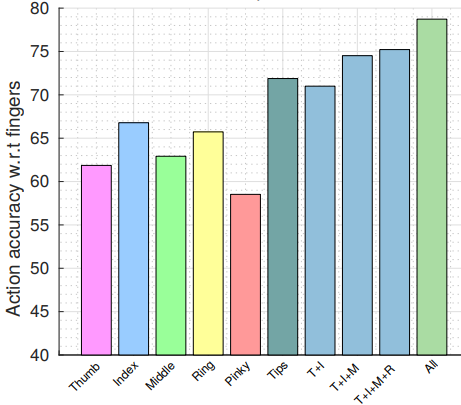
- action recognition 정확도에 기여하는 각 손가락 contibution를 나타낸다.
- 각 손가락별로는 index가 가장 의미가 있고, fingertips 또한 성능이 높다.
- contibution이 높다는 것은 hand pose를 더 잘 설명할 수 있다는 의미이다.
6.1.2. State-of-the-art evaluation
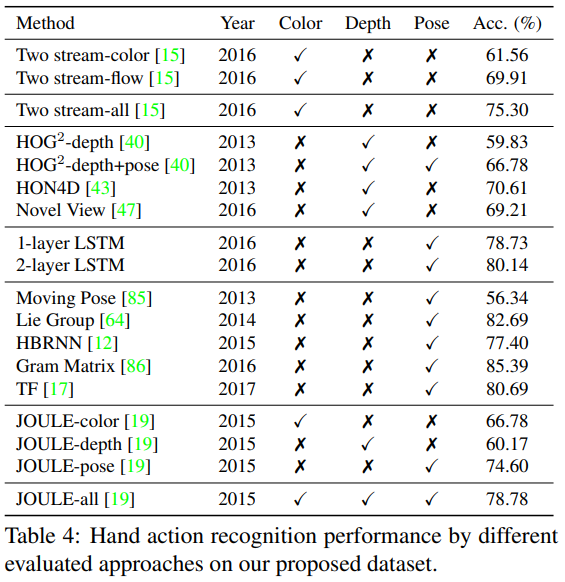
- Spatial and Temporal cues [15]
- 좋은 성능을 내었다.
- Depth
- 다른 method에 비해 낮은 성능을 내었다.
- hand pose 또는 object을 제대로 인지하지 못함을 의미한다.
- Synthetic views of bodies [47]
- hand pose에 제대로 일반화되지 못하였다.
- Hand pose [86, 64]
- 가장 높은 성능을 달성하였다.
Hand pose vs depth vs color
- JOULE를 각각 color, depth, pose로 나누어 각각의 중요도를 파악할 수 있도록 함을 목표로 실험하였다.
- color, depth, pose중에 Hand pose가 가장 높은 성능을 내며, 중요한 인자임을 알 수 있다.
Object pose
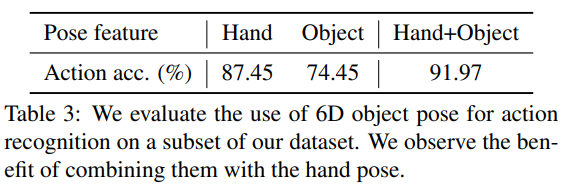
- 4가지의 annotated된 object에 대해 LSTM baseline을 Train하였다.
- 위 표를 통해, Train의 결과로써 두 feature를 모두 사용하였을 때, 가장 성능이 높으므로 Hand pose와 Object pose는 상호보완적임을 알 수 있다.
6.2. Hand pose estimation
Training with objects vs. no objects
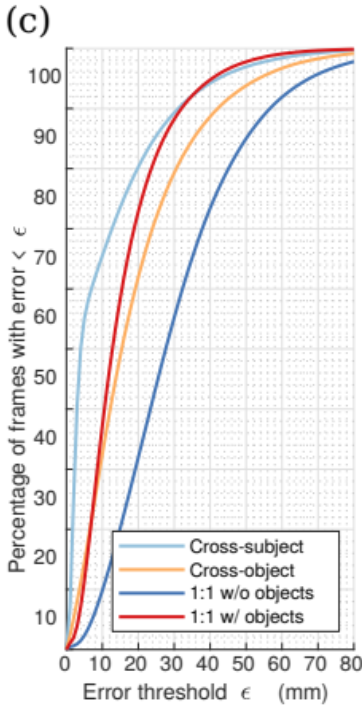
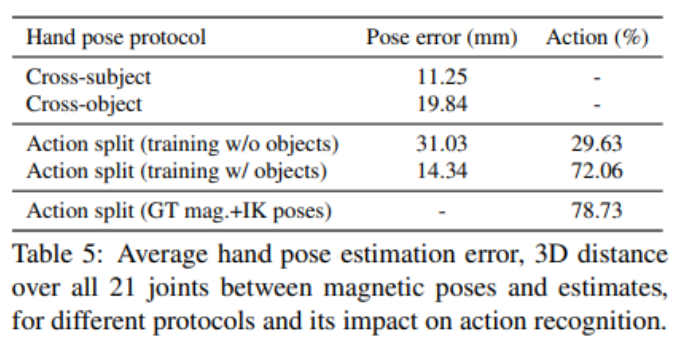
- Object를 포함한 이미지와, 포함하지 않은 이미지를 학습시켰을 때, Hand-Object을 포함한 이미지로 학습된 모델이 더 좋은 성능을 냈다.
- Actor를 기준으로 3명 씩 반으로 나눠 Train과 Test를 진행하고, Object를 기준으로 반씩 나눠 Train과 Test를 진행한다. 결과: unseen subject는 일반화될 수 있지만, unseen object는 일반화되기 어렵다는 것을 알 수 있다.
따라서 Object와 상호작용하는 내용을 담은 hand pose가 hand action recognition에 중요한 인자라는 것을 알 수 있다.
7. Concluding remarks
- 새로운 benchmark 데이터셋을 제안하였고, 이 데이터셋으로 RGB-D, pose를 기반으로 한 다양한 모델의 hand action recognition을 평가하였다.
- benchmark은 temporal action labels과 3D hand pose labels, 부분적으로 6D object pose labels를 제공하였다.
- 다양한 baseline test를 통해, hand pose feature가 action recognition에 중요한 요인임을 확인하였다.
댓글남기기