
[논문 리뷰] Fate/Zero: Fusing Attentions for Zero-shot Text-based Video Editing
https://arxiv.org/pdf/2303.09535.pdf
오늘은 Fate/Zero: Fusing Attentions for Zero-shot Text-based Video Editing 논문을 리뷰하려고 한다. 이 논문은 Video Editing 분야의 논문 중 하나이며, 최근 ICCV 2023에 등재되었다.
이 논문을 통해서 얻고 싶은 것은,
- Text를 기반으로 어떻게 Video를 편집을 하는지 원리를 알아보고 싶고,
- 어떻게 프레임 간의 객체가 변형되지 않고, 자연스럽게 유지될 수 있는지 알아볼 것이다.
1. Abstract
이 논문은 기존에 사전 학습된 diffusion model을 사용해서 두 가지 Zero-Shot Task를 진행하였다.
- 국부적인 객체의 모양을 수정하는 Task
- 비디오 스타일 수정하는 Task
이 논문에서는 zero-shot 텍스트 기반의 비디오 에디팅 방법론인 Fate-Zero를 제안한다.
프롬프트를 학습할 필요도 없고, 방법론에 맞는 특정 mask도 필요가 없다.
어떻게 일관적으로 비디오를 수정하는가?
- DDIM의 inversion 과정 중간에 Attention map을 저장한다.
- 그 attention map에는 structural, motion information이 포함되어 있다. => 굿b
- 모든 의미적인 정보를 충분히 표현하지 못하는 것을 막기 위해서 ⇒ self-attention과 blending mask를 결합했다.
- self-attention은 주어진 시퀀스 내의 각 요소 간의 상관 관계를 계산하는 메커니즘이다. 이를 통해 입력 시퀀스의 각 요소가 다른 요소와 얼마나 관련되어 있는지를 알 수 있다.
- cross-attention은 두 개 이상의 서로 다른 시퀀스의 관련성을 측정하는 메커니즘이다. 예를 들어, 번역 작업에서 입력 문장과 출력 문장 간의 관련성을 계산하여 번역을 수행하는 데 사용된다.
- blending mask ⇒ cross-attention을 통해 나온 mask
- Denoising U-Net 내부의 self-attention 매커니즘을 수정했다
- 어떻게? ⇒ spatial-temporal attention으로 self-attention을 업그레이드해서 프레임이 일관성을 갖도록 하였다.
2. Introduction
기존의 방법론에서의 생성 Prior 가지고 비디오를 조작하는데는 몇 가지 어려움이 있다.
- 일반적으로 사용할 수 있는 text-to-video 모델이 없다. 즉 시간적인 정보를 고려한 모델이 없다는 의미이다.
- 시간적인 정보: 동작, 3차원 공간의 사물 이해
- text-to-image 모델을 비디오에 적용하면, 시간적인 정보를 고려하지 못해, 깜박이는 듯한 문제(flickering)가 발생한다.
- 기존에 존재하는 Video Editing 모델의 문제
- 도메인에 맞게 학습을 추가적으로 해야하거나, 직접 keyframe을 선정하거나, 프롬프트 각각 튜닝하는 등이 필요하다
- Keyframe: 영상 내용의 핵심을 잘 나타내는 프레임
- 물체의 모양을 변경하는 기능은 없다. (컬러 등 스타일을 변경하는 기능이 대부분이다)
- 도메인에 맞게 학습을 추가적으로 해야하거나, 직접 keyframe을 선정하거나, 프롬프트 각각 튜닝하는 등이 필요하다
- DDIM에서 노이즈를 추가할 때, 완전한 노이즈 시점 T까지 가게되면, 원본 비디오가 왜곡될 수 있다.
논문에서 제안하고자 하는 부분
- 각 프롬프트에 대해서 추가적으로 학습할 필요가 없다.
- user-specific mask를 사용하지 않는다.
- user-specific mask는 사용자별로 특정한 목적이나 요구에 맞게 제공되는 마스크를 의미한다.
- 원본 비디오를 학습하지 않고, edit된 비디오의 시간적 일관성을 유지한다.
위의 세가지를 구현하기 위해서 두 가지 구조를 제안했다.
- noising(forward) process의 매 step마다 self-attention maps과 cross-attention maps을 저장하고 denoising 과정에 사용하여 대체할 수 있다. 하지만 여기서 무엇을 무엇으로 대체하는지?
- 이전 방법에서는 단순히 noising과 denosing의 과정만 거쳤다.
- self-attention 구조는 동작 정보를 잘 저장하고, cross-attention은 self-attention들이 공간적으로 잘 결합될 수 있도록 하는 역할을 한다.
- self-attention을 spatial-temporal self-attention으로 업그레이드해서 appearance가 일관적으로 유지할 수 있도록 하였다.
이 논문에서 기여하고자 하는 부분은 다음 4가지가 있다:
- 사전학습된 text-to-image model을 사용하여, temporal-consistent한 zero-shot text-based video editing 프레임 워크를 제안하다.
- inversion(forward) 과정에서 Attention map을 결합시켜, editing할 때, 동작과 구조의 일관성을 유지할 수 있다.
- Attention Blending Block에서 cross-attention map을 사용하여 self-attention이 잘 결합될 수 있도록 하였고, 이로 인해 의미적인 정보를 충분히 표현하고, 물체의 shape editing의 성능을 높일 수 있다.
- 실제로 video style editing과 video local editing, video object replacement 등 다양한 적용 사례를 보여줬다.
3. Method
이 논문에서는 Stable Diffusion과 Stable Diffusion을 기반으로 만들어진 대표적인 Video Generation 모델인 Tune-A-Video 모델을 사용하였다.
3.1. Preliminary: Latent Diffusion and DDIM Inversion
3.1.1. Latent Diffusion Models (LDMs)
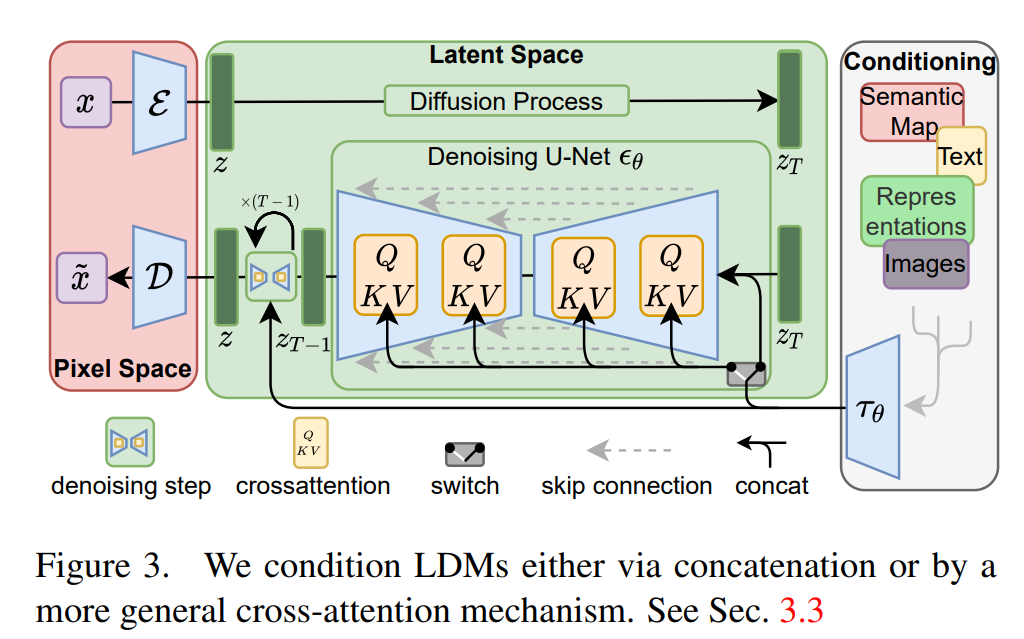
LDMs: Autoencoder의 latent 공간에서 노이징을 하고 디노이징하는 모델이다.
-
AutoEncoder: encoder가 RGB 이미지를 저차원 잠재 공간으로 압축하고, decoder를 통해서 잠재 공간을 이미지로 복원할 수 있다.
- $z = E(x)$: 이미지 $x$를 오토인코더의 인코더를 거쳐 나온 값이다.
- $D(z)$: 디코더를 통해 이미지를 복원한다.
-
U-Net: cross-attention과 self-attention을 포함하고 있으며, 노이즈를 제거하도록(denoising) 훈련된다.
-
$ε_θ$: U-Net이다. 아래 목적 함수를 통해 노이즈를 제거한다.
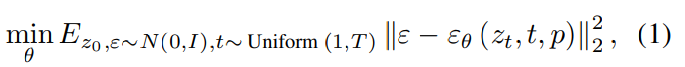
- $p$는 텍스트 프롬프트의 임베딩이다.
- $z_t$는 $z_0$에 t번의 step을 거쳐 노이즈를 추가한 것이다.
-
3.2. FateZero Video Editing
사전학습된 text-to-image 모델 중 하나인 Stable Diffusion을 베이스 모델로 사용하였다.
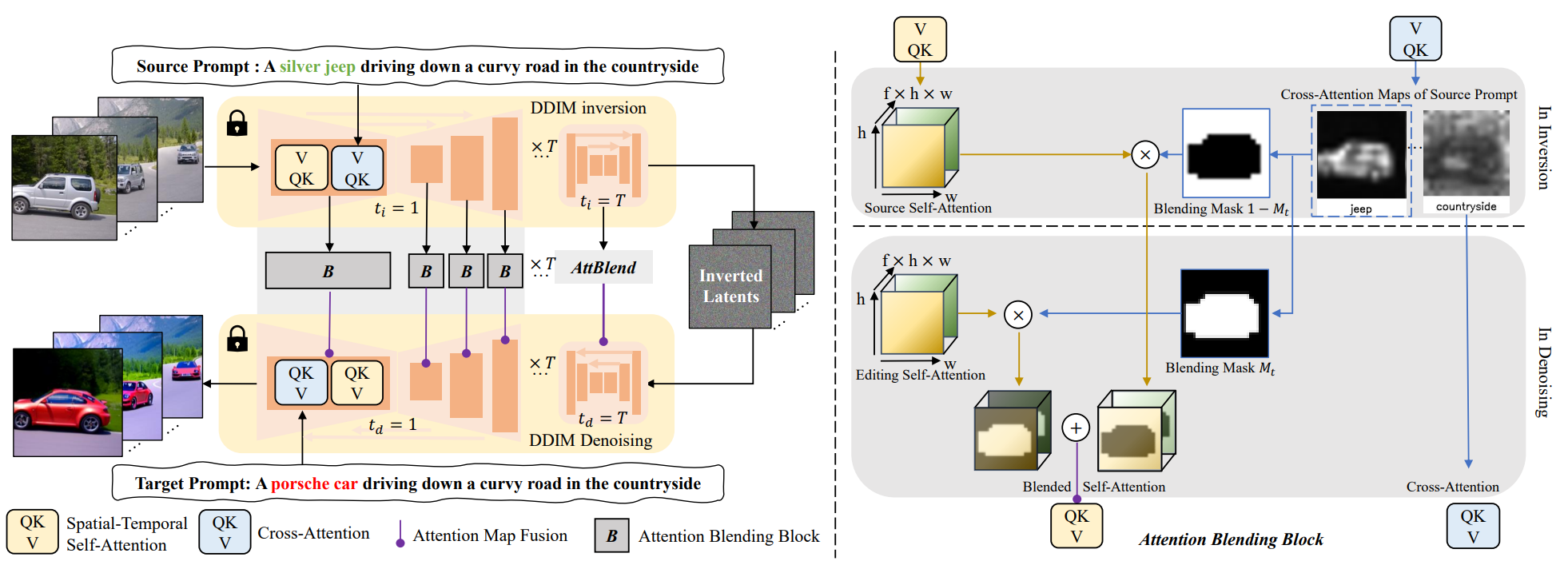
3.2.1. Structure
- DDIM inversion: (source prompt와 inflated 3D U-Net ε_θ을 통해) Video를 noise latent zT로 만든다.
- 노이즈를 입히는 각 스텝 t마다, spatial-temporal self-attention maps($s_t^{src}$)와 cross-attention maps($c_t^{src}$)를 저장한다.
- DDIM denoising: $z_T$를 조건 target prompt($p_{edit}$)가 반영된 clean image로 디노이징한다.
- 디노이징하는 각 스텝 t마다, (논문에서 제안된 Attention Blending Block을 통해) $s_t^{edit}$, $c_t^{edit}$와 $s_t^{src}$, $c_t^{src}$를 융합한다.
- road, countryside와 같이 수정할 필요가 없는 부분의 denosing 단계의 cross-attention($c_t^{edit}$)부분을 noising 단계의 cross-attention($c_t^{src}$)부분으로 대체한다.
- (noising 과정의 cross-attention($c_t^{src}$)을 통해 얻어진 adaptive spatial mask를 이용해서) $s_t^{src}$와 $s_t^{edit}$를 융합한다.
- 디노이징하는 각 스텝 t마다, (논문에서 제안된 Attention Blending Block을 통해) $s_t^{edit}$, $c_t^{edit}$와 $s_t^{src}$, $c_t^{src}$를 융합한다.
- source cross attention에서 jeep과 countryside에 해당하는 이미지를 구분한다. jeep은 수정해야할 부분, countryside는 유지해야할 부분이다.
- cross attention을 통해 2가지 blending mask를 얻는데, 하나는 source self-attention과 결합할 마스크, 다른 하나는 editing self-attention과 결합할 마스크이다.
- source self-attention과 결합할 마스크는 jeep 부분에 해당하는 픽셀이 0, 나머지 부분은 1이다. editing self-attention과 결합할 마스크는 반대에 해당한다.
- source self-attention과 마스크($1-M_t$) 가 결합하고, editing self-attention과 마스크 ($M_t$)가 결합한다. 결합된 두 값은 더해져서 Spatial-Temporal Self-Attention으로 들어간다.(Blended Self-Attention)
- cross attention을 통해 2가지 blending mask를 얻는데, 하나는 source self-attention과 결합할 마스크, 다른 하나는 editing self-attention과 결합할 마스크이다.
3.2.2. Inversion Attention Fusion
inverted latents인 $z_T$에서 바로 editing하는 것은 Frame inconsistency를 발생시킨다. 그 이유는 2가지가 있다.
- DDIM에서 denoising 과정에서 50 step을 거치는데, 이는 diffusion 모델의 noising step과 비교했을 때, step 간격이 상대적으로 크기 때문에 error가 축적되는 결과를 초래한다.
- large classifier-free guidance ($s_{cfg}$ » 1)를 사용하면 denoising 과정에서 편집 능력을 향상시킬 수 있지만, 큰 편집 자유도는 일관성 없는 이웃 프레임으로 이어질 수 있다.
- 위의 두 가지 문제를 해결하기 위해서 noising 과정에 attention maps를 도입했다.
- noising 과정에서 U-Net에 z_0와 source prompt를 입력으로 넣는다. 매 noising step마다 self-attention maps, cross-attention maps를 저장한다.
- 총 T개의 intermediate self-attention maps와 cross-attention maps 그리고 최종 latent feature map인 z_T를 저장한다.
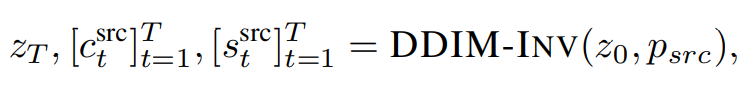
- DDIM의 noising 과정
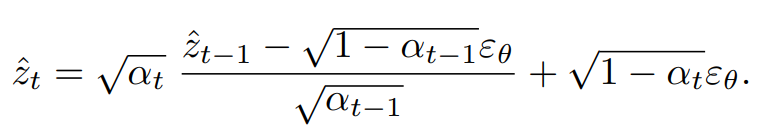
- DDIM의 noising 과정
- denoising(editing) 과정에서는
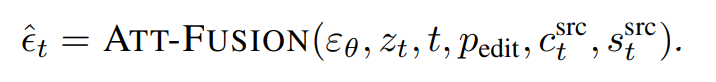
- attention-fusion에 수정할 필요가 없는 부분의 cross-attention maps을 넣었다.
- editing하는 도중에 원본의 구조와 모션이 유지될 수 있도록 한다.
- DDIM의 denoising 과정:
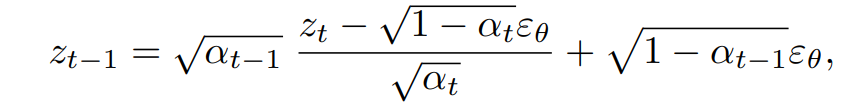
- noising 과정에서 cross-attention map은 (a)와 (b)에서 큰 차이가 발생하지 않았다. 하지만 reconstruction 과정에서 큰 차이가 발생했다.

- 왜 reconstruction에서 attention을 준 것보다 noising 과정에서 attention을 준 것이 consistency를 유지할 수 있을까? ⇒ 원본 구조를 더 잘 유지할 수 있기 때문일까?
- spatial-temporal self-attention maps이 프레임간의 유사성을 표현한다.
3.2.3. Attention Map Blending
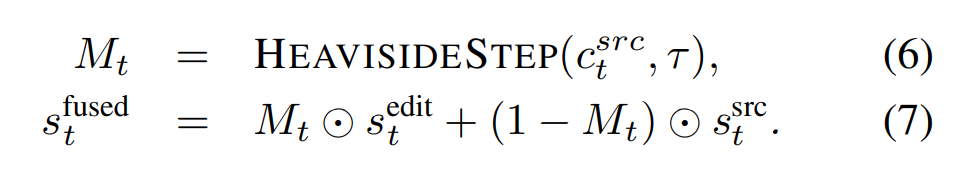
- noising 과정에서 cross-attention map을 사용하여 수정이 필요한 부분을 1로 두는 binary mask M_t를 얻는다. 수정이 필요하지 않은 부분은 1-M_t이다.
- binary mask M_t를 통해서 $s_t^{src}$와 $s_t^{edit}$를 융합한다. ⇒ $s_t^{fused}$

- 4번째, 5번째 열은 원본 이미지의 구조 또는 배경을 유지하지 못했다.
- 반면 2번째 열의 cross-attention을 사용해서 self-attention을 blending한 것은 원본 이미지의 구조와 배경을 유지한 채로 edit 되었다.
3.2.4. Spatial-Temporal Self-Attention
위의 두 가지 방법을 도입해도 여전히 inconsistent video가 될 수 있다. 그렇기에 spatial-temporal self-attention으로 self-attention을 재구성하여 single frame의 구조와 temporal 관련성을 이해할 수 있도록 하였다.
3.3. Shape-Aware Video Editing
사전학습된 video diffusion 모델인 Tune-a-video 모델로 진행하였다.
단순히 DDIM inversion을 한 방식과 spatialtemporal attention maps을 적용한 방식을 비교했을 때, 후자가 더 좋은 성능을 나타냈다.
4. Conclusion
지금까지 Fate/Zero 논문을 읽었다. 이제까지 읽은 Video Editing 논문 중에 Consistency를 유지하며 가장 성능이 좋은 것 같다. 원본의 구조를 유지하며 필요한 부분을 수정한다는 점에서 굉장히 흥미롭게 읽었다.
댓글남기기