
[논문 리뷰] Egocentric View Hand Action Recognition by Leveraging Hand Surface and Hand Grasp Type
오늘은 hand action recognition을 위해서 Hand Grasp Type을 사용하는 논문을 읽어볼 것이다.
1. Introduction
1.1. 연구 소개
논문에서는 객체의 6D, 3D 정보를 사용하지 않고 grasp type, hand surface mean curvature, temporal frame을 사용하여 1인칭 시점의 손 동작 인식의 성능을 높이는 방법을 제안하였다.
1.1.1. hand action recognition에서의 grasp type & hand Surfaces 필요성
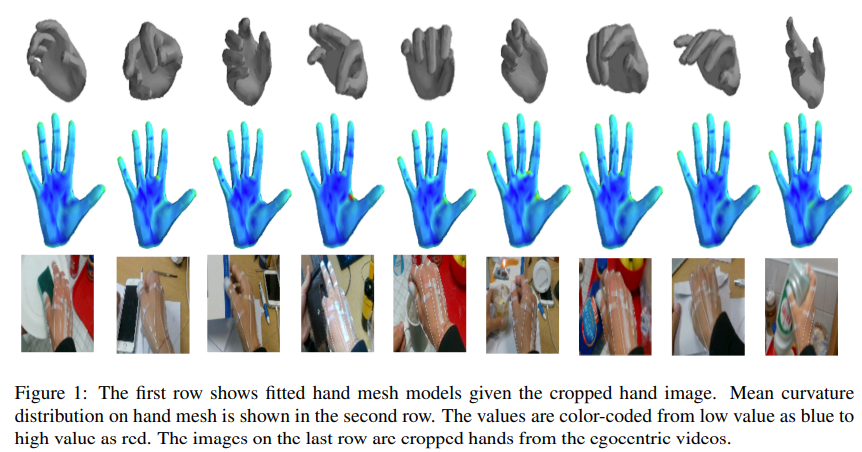
손 제스처와 다르게 손 동작은 객체와 상호작용하므로 객체를 포함한 grasp type을 이해해야하며, 손 동작에 따라 손 표면도 달라지므로 hand surface 또한 고려해야한다. 따라서 객체와 상호작용하는 손 동작 인식을 위해 grasp type과 hand surface가 중요하다는 것을 알 수 있다.
1.1.2. Hand Action의 Challenges
- 다양한 형식의 rigid, non-rigid 물체를 잘 이해해야한다. ex_ 컵 - rigid, 손 - non-rigid
- 손, 물체 등으로 인해, 손 등, 손가락 등 손의 일부가 가려지는 문제를 해결해야한다.
- 카메라를 빠르게 움직이면, 손 동작 예측하기 어려운 문제가 있다.
1.1.3. 선행 연구
위의 Challenges를 해결하기 위해 Computer vision community에서는 depth sensors와 multiple cameras를 통합하여, 3D와 6D로 다양한 방식의 손 동작(손과 물체의 상호작용)을 인식하였다.
하지만 이러한 방식은 다음과 같은 문제가 존재한다.
- 6D로 객체를 표현할 때, 발생하는 객체 공간의 복잡도와, 6D상에서 손 동작과 객체간의 관계에 annotate할 때에 많은 cost가 발생한다.
- depth sensor는 높은 휘도에 약하며, RGB 카메라보다 비싸다.
- 손 표면과 손 동작의 관계를 고려하지 않았다.
- multi-camera는 보정과, 프레임들의 동시성을 고려해야하므로 비효율적이다.
1.1.4. Contributions
- 새로운 손 동작 추정 파이프라인을 제시하였다. 손 표면의 mean curvatures는 손 표면의 기하학적인 정보를 보여주며, mean curvatures를 계산할 때, 전체 이미지 중에 손 부분만 필요하므로 location-invariant한 특징이 있다.
- 3D information없이, hand grasp types 인식을 통해 손과 물체의 interaction을 학습하는 방법론을 제시하였다.
- 물체와 상호작용하는 다양한 grasp types을 포함한 taxonomy를 수립하였다.
- 다양한 hand grasp type으로 hand action을 정의하였다. ⇒ 한 프레임 내에서 grasp type을 예측하고, temporal neural networks를 통해 hand action estamte 성능을 높였다.
Hand Surface과 Hand Grasp Type을 이용한 hand action recognition은 기존 SOTA 모델의 성능을 능가했다.
2. Related Work
2.1. Hand action recognition
Hand action recognition을 위해 기존에 사용된 방법들은 다음과 같다.
- hand pose는 객체의 geometry와 grasp type을 담고 있으며, depth sensor를 통해 3D hand poses를 측정한다.
- Tekin et al.: Hand action recognition을 위해 hand와 object의 상호작용을 고려한다.
- Li et al.: 손을 움직이는 상황에서, 시선이 향하는 부분을 주목하고, 그 부분에서 중요한 특징을 추출한다.
- sequence of frame. 즉, frame들 간의 temporal relation에 주목한다.
- Aksoy et al.: action과 object 사이의 관계에 semantic meaning을 적용하여 hand action을 인식한다.
2.2. Surface curvature in non-rigid object
손과 같은 non-rigid object는 형태가 계속 변화하므로 surface information을 통해 분석할 수 있다.
non-rigid object의 표면을 분석하기 위해서는 curvature을 사용한다.
- Limberger et al.: curvature기반으로 non-rigid object 분석
- Laskov et al.: Gaussian curvature와 non-rigid object의 관련성을 분석하여 모션을 추정한다.
- Deboeverie et al.: 인간의 신체의 curvature를 기반으로 신체를 구분한다.
- Chen et al.: pixel 공간의 curvature로 human action을 인식한다. curvature가 시공간적인 특징을 나타낸다는 것을 확인하였다.
- Chang et al.: curvature scale 공간에서 변환, 확장, 회전에 변하지는 않는 속성을 가잔다는 것을 제안한다.
위 논문에서는 mean curvature를 사용하여 hand action을 인식하고자한다.
2.3. Hand grasp type for hand action
grasp type은 손과 관련된 작업을 할 때, 사람의 의도를 표현한다. 따라서 많은 연구에서 grasp type taxonomy을 만들었다.
- Feix et al.: 정적이고, 안정적인 grasp type의 taxonomy를 생성하였다.
- Cutkosky et al.: grasp 분석 모델 설계하여 제조업의 로봇 hand를 디자인하였다.
- Yang et al.: grasp type의 통해 인간의 의도와, 판단을 예측하였다.
- Cai et al.: grasp type과 object의 관계를 학습시켜 hand action 인식을 하였다.
하지만 관련 논문에서는 pre-grasp type을 다루지 않았다. 따라서 위 논문에서는 pre-grasp type을 포함한 taxonomy를 제안하고자 한다.
3. Method
1인칭 시점에서 RGB 카메라를 통해 촬영한 영상의 Hand action을 예측한다.
3.1. Hand and Object Detection
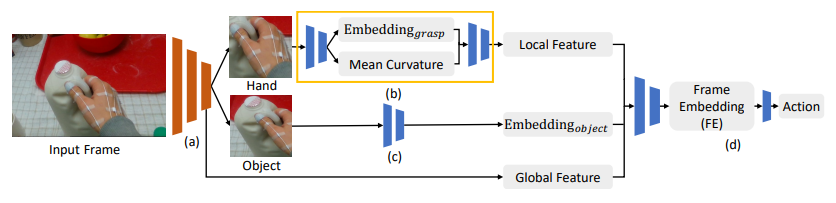
Object Detection Network를 통해 Input Frame에 존재하는 primary hand(오른손으로 설정)와 target object를 인식한다. object detection을 하기 위해서는 primary hand와 target object에 대한 라벨링을 하며, 라벨링된 데이터로 object detection network를 개선한다.
또한 object detection의 output으로 primary hand와 target object의 관계가 인코딩되고, global feature로 Frame Embedding을 만드는 레이어의 input으로 들어가게된다.
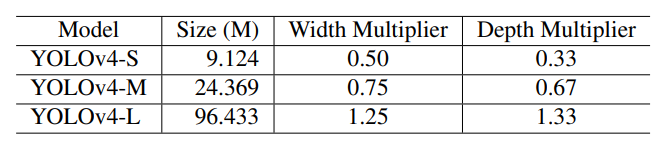
Object detector로는 YOLOv4를 사용하였고, depth와 width를 다르게하여 아래 세 모델을 사용하였다.
3.2. Local Network
Local Network는 다음과 같이 2개의 네트워크로 구성되며 pre-trained ResNet34을 backbone으로 사용하였다.
-
Hand grasp type estimator
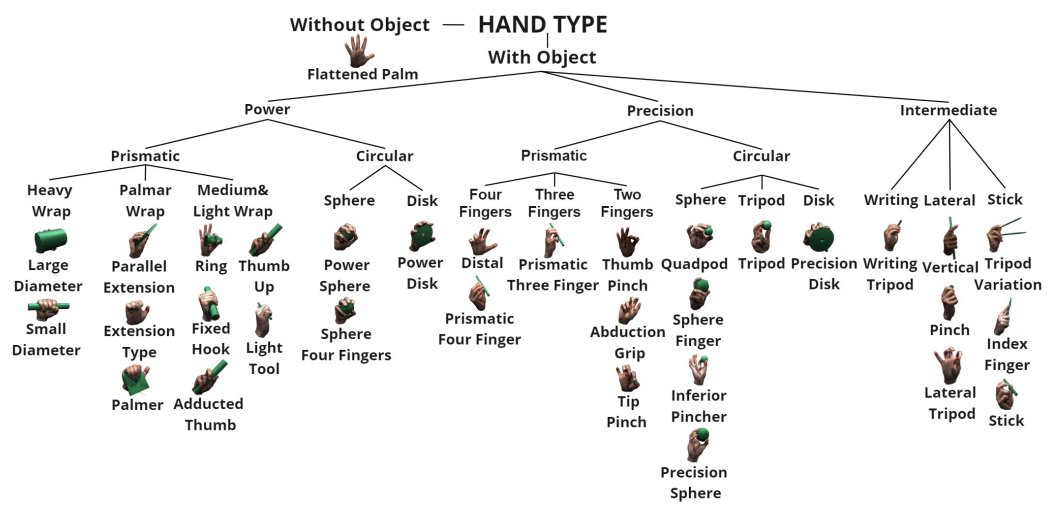
- grasp type의 taxonomy을 통해 손이 물체에 가려지는 문제를 해결한다.
- hand type의 taxonomy는 물체를 쥐고 있는 손과 물체를 쥐고 있지 않는 손 모두를 포함한다.
- primary hand가 crop된 이미지에서 taxonomy를 활용하여 hand type을 분류 예측하고 grasp embedding을 얻는다.
-
Mean curvature estimator
- hand의 세밀한 변화를 담기 위해 Mean curvature가 사용되며, 이는 손의 local surface를 표현할 수 있고, 또한 손 부분을 통해서 측정하므로 global position이 변하여도 측정 결과는 변하지 않는다.
- hand Grasp Type의 중간 벡터를 concatenate하여 mean curvature를 계산한다.
- MANO hand mesh model을 사용하여 각각의 tervex의 mean curvature을 계산하였다.
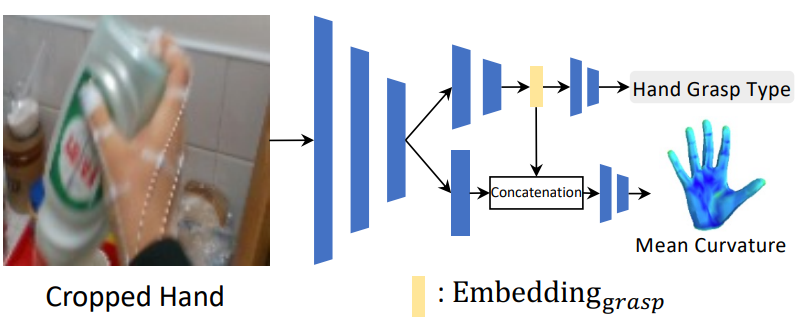
두 estimator는 hand cropped image를 사용하며 동시에 계산 가능하다.
3.3. Frame Embedding and Temporal Model
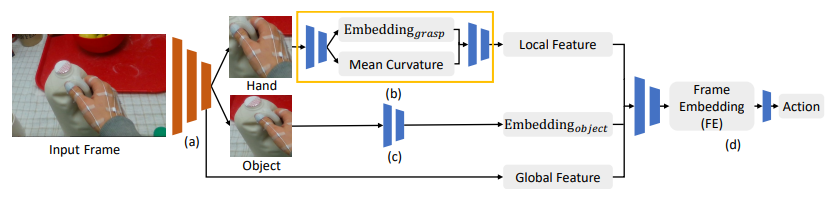
3.3.1. Frame embedding generator
Frame embedding generator는 다음과 같이 4개의 네트워크로 구성되었다.
- object detection network
- Input Frame에서 primary hand 와 target object를 인식하고 primary hand와 Object의 특정 부분만 crop한다.
- 또한 primary hand와 target object의 관계를 나타내는 embedding을 추출한다.(Global Feature)
- local feature network
- primary hand가 crop된 사진에서 grasp type과 mean curvature embedding을 추출한다. (Local Feature)
- object embedding network
- target object가 crop된 사진에서 object embedding을 추출한다. (Embedding object)
- mixture network
- (a), (b), (c)에서 추출된 3개의 embedding을 통합하여 Frame Embedding(FE)을 만든다.
3.3.2. Temporal model for action recognition
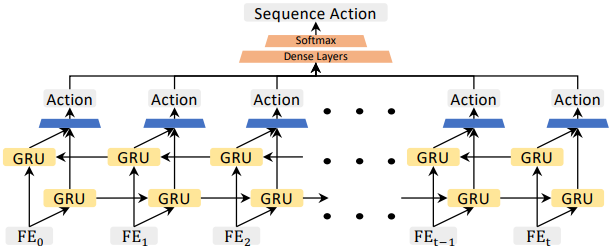
Hand action은 정적인 상태가 아니라 연속적인 상태이므로 temporal information을 인코딩할 필요가 있다.
Hand action의 temporal relation을 담기 위해 양방향의 GRU(Gated Recurrent Unites)를 사용한다.
각 GRU의 output은 action을 예측하고, 각 action embedding들은 세 개의 fully-connected layers로 결합된다. 3개의 fully-connected layers를 거쳐 최종 hand action을 예측한다.
3.4. Loss Function
(α=0.3, β=0.2, and κ=0.5)
3.4.1. Frame embeding generator
-
object detection network
object detection은 별도로 YOLOv4의 loss function으로 훈련한다.
-
local network
local network는 아래의 loss function으로 최적화한다.
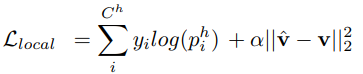
-
object network
object network는 아래의 loss function으로 최적화한다.
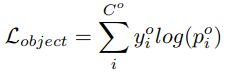
-
mixture network
위 3개의 network을 최적화한 다음, mixture network를 아래의 loss function으로 최적화한다.
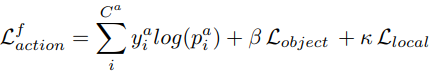
3.4.2. Temporal model
Frame embedding generator를 최적화한 뒤, network의 파라미터를 freeze한 후에, 아래의 loss function으로 최적화한다.
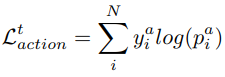
4. Experiment
4.1. Dataset
First-Person Hand Action(FPHA) 데이터셋을 사용하였다. 이 데이터셋은 MANO Hand Model에 사용된 데이터셋이다.
FPHA는 1175개의 비디오, 6개의 subject, 24개의 서로 다른 object, 45개의 서로 다른 hand action category를 포함한다.
FPHA의 작은 버전인 TinyFPHA은 10개의 action을 담고 있다.
수작업으로 비디오의 각 프레임에 hand action에 대한 주석을 달았다.
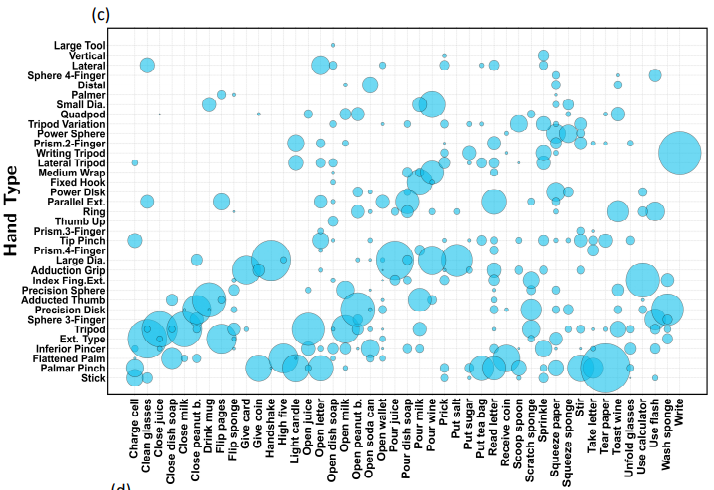
위 그래프를 통해, 한 가지 action에 대해서 여러 hand type이 존재한다. 따라서 hand type만 보고 hand action을 예측하는 것은 바람직하지 않다는 것을 알 수 있다.
4.2. Experimental Results
4.2.1. Object detection network and object network
object detection network에서 YOLOv4가 사용되었고, 모델을 평가 측도로는 mAP와 gIoU를 사용하였다. 성능 결과는 다음과 같다.

object network에서는 pretrained ResNet18가 backbone으로 사용되었고, 36개의 fully-connected layer로 구성되었다. learning_rate는 0.0001, epoch는 30, batch size는 32로 설정하여 훈련하였다. Test set에서는 96.42%의 정확도를 달성하였다. local network와 Mixture network를 학습한 후에는 성능이 98.52%로 향상되었다.
4.2.2. Ablation studies and implementation details
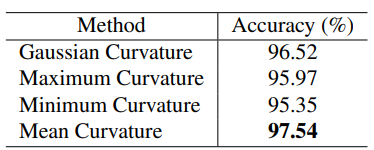
-
hand grasp type
ResNet18로 hand grasp type classification 진행하였고 97.32%의 정확도를 달성하였다. hand action의 정확도보다 낮은데, hand grasp type이 long tail 분포를 가지기 때문이다.
-
hand curvature
hand grasp type의 embedding 벡터와 concatenate하여 hand curvature를 예측한 결과, L2 loss가 3.238이 나왔다.
4.2.3. Comparison with other methods
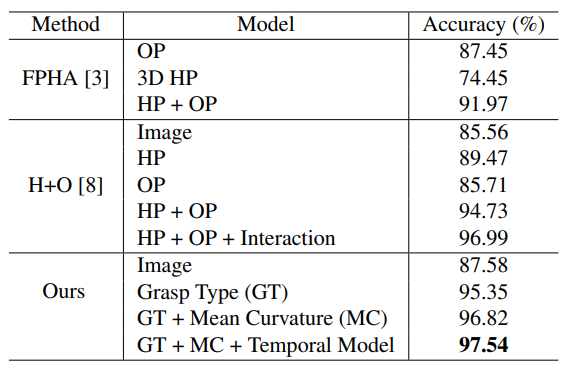
OP: 6D Object Pose
HP: 3D Hand Pose
Grasp Type, Mean Curvature, Temporal Model을 적용한 모델이 6D Object Pose, 3D Hand Pose, Interaction 등을 적용한 모델의 모든 성능을 뛰어 넘는다는 것을 알 수 있다.
5. Conclusion and Future Work
5.1. Conclusion
Hand action recognition에서 6D object pose와 depth 카메라를 사용하지 않고, Hand grasp type과 Hand mean curvature, Temporal model을 사용한 방식을 제안했다.
이러한 방식은 기존의 SOTA 모델의 성능을 월등히 뛰어넘었다.
5.2. Future work
Hand grasp type, Hand mean curvature, Temporal model을 적용한 방식을 1인칭 시점뿐만 아니라, 다인칭 시점도 고려하여 더욱 일반적인 경우에 적용할 수 있도록 한다. 이는 object와 상호작용하는 3D hand pose 예측도 가능하게한다.
댓글남기기