
[논문 리뷰] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
DreamBooth: https://dreambooth.github.io/
https://arxiv.org/pdf/2208.12242.pdf
DreamBooth 논문은 기존 diffusion 모델에서 학습되지 않은 데이터를 기반으로 이미지를 생성하고 싶을 때, 발생하는 문제점을 해결한 모델이다.
Diffusion의 Denoising과정을 fine-tuning하여 customize한 데이터를 생성할 수 있다. 즉, diffusion으로 내 초상화도 그릴 수 있는 모델이다.
Approach
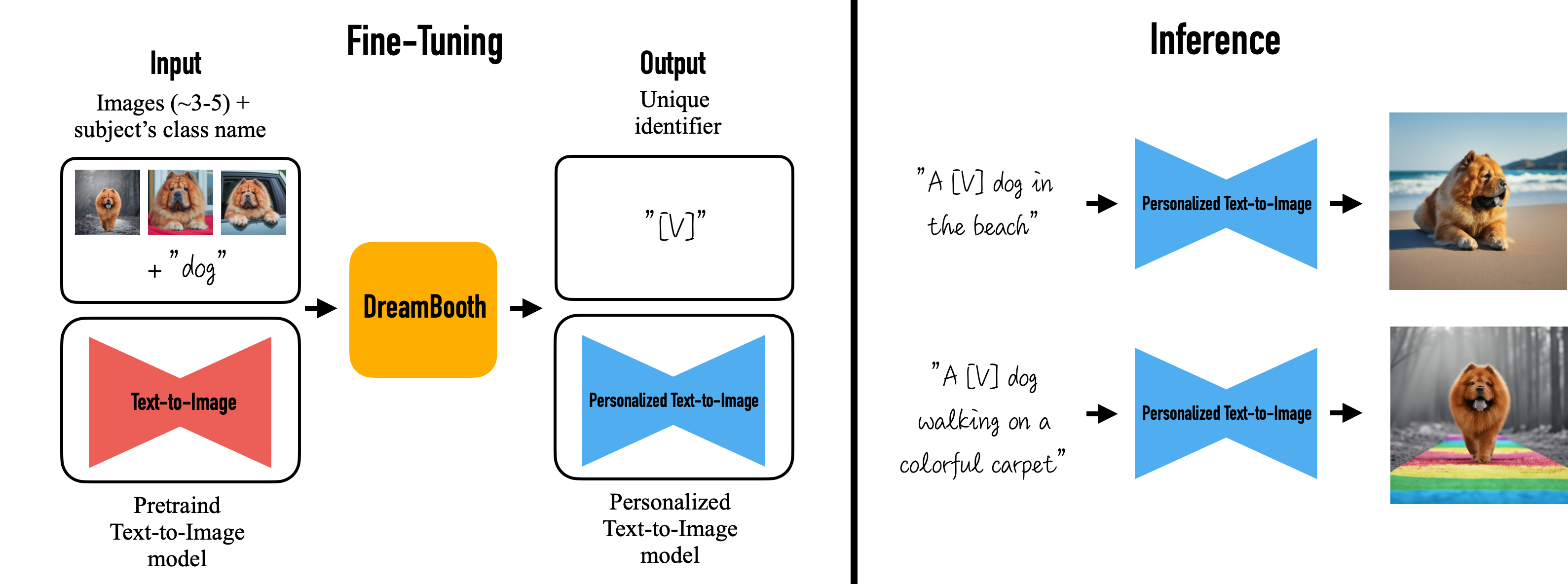
Fine-Tuning Text-to-Image diffusion
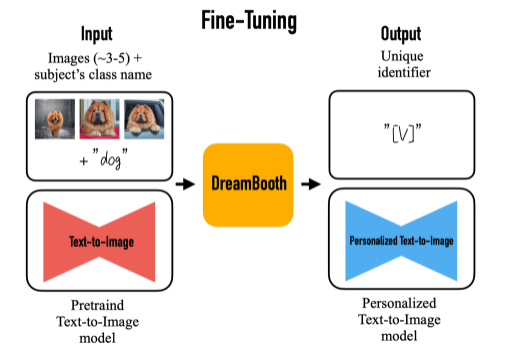
- low-resolution text-to-image model을 fine-tuning한다.
- input image와 text prompt(“A photo of a [T] dog”) 쌍으로 diffusion model을 fine-tuning한다.
- text prompt는 unique identifier([T])와 class name(dog)으로 구성된다.
-
class-specific prior preservation loss 적용
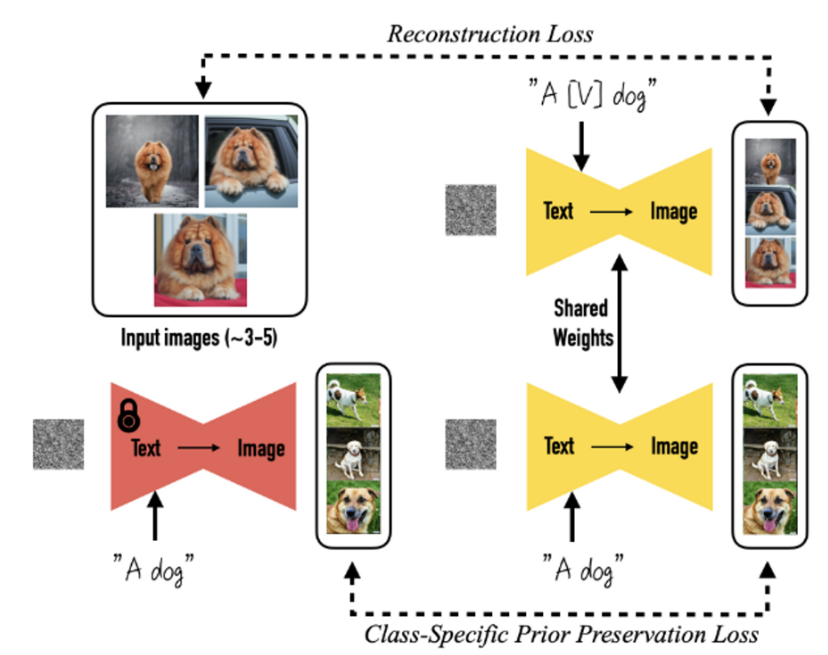
- 클래스 이름을 text prompt에 넣어도 (e.g., “A photo of a dog”) dog라는 클래스 prior가 유지될 수 있도록 위의 fine-tuning과 함께 학습한다.
- input image와 text prompt(“A photo of a [T] dog”) 쌍으로 diffusion model을 fine-tuning한다.
- super resolution components를 fine-tuning하여 높은 해상도 이미지를 얻는다.
- input images set의 low-resolution과 high-resolution image쌍으로 fine-tuning
⇒ 작은 디테일에 대한 높은 정확도 유지 가능
- input images set의 low-resolution과 high-resolution image쌍으로 fine-tuning
Inference
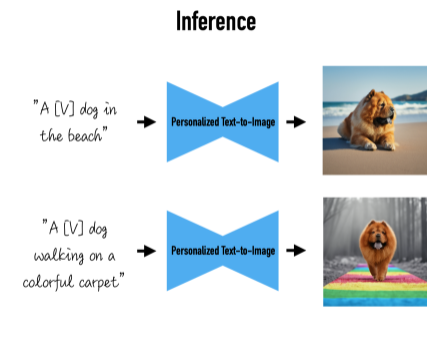
- unique identifier를 다른 문장들에 넣고, personalized text-to-image 모델을 통해 이미지를 생성한다.
1. Abstract
- 기존 Text-to-Image 모델의 문제점:
- 주어진 reference set에 존재하는 대상의 모습을 모방하여 생성하는 능력이 부족하다.
- 다양한 맥락에서의 새로운 renditions 합성하는 능력이 부족하다.
- 논문에서 기여하고자 하는 부분
- “Personalization” of Text-to-Image 모델을 제시한다.
- 방법
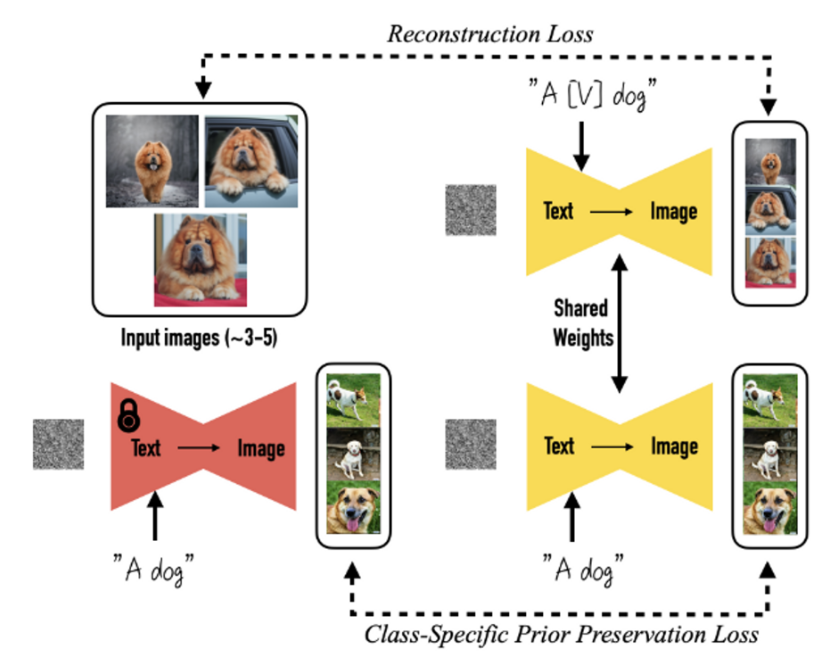
- 대상의 3-5개의 이미지를 가지고 사전 학습된 text-to-image 모델을 fine-tuning 한다.
- 사전 학습된 모델을 고유한 identifier와 주어진 대상을 묶도록 fine-tuning한다.
- 그 다음, 고유한 identifier를 사용하여 주어진 대상을 다양한 환경의 이미지로 합성한다.
- a new autogenous class-specific prior preservation loss를 적용한 모델에 인코딩된 semantic prior를 사용하여 다양한 장면, 포즈, 시점, 빛 조절 등 주어진 대상을 합성할 수 있다.
- 대상의 3-5개의 이미지를 가지고 사전 학습된 text-to-image 모델을 fine-tuning 한다.
- 주어진 대상의 key features를 보존하는 task에 적용하는 실험도 진행하였다. (subject recontextualization, text-guided view synthesis, and artistic rendering 등)
2. Introduction
2.1. 기존 Large text-to-image models
- 장점
- 대규모의 이미지-텍스트 쌍 데이터쌍으로 학습되어 strong sematic prior를 얻을 수 있다.
- 예시: sematic prior는 “dog”라는 단어와 다양한 예시들의 강아지 이미지들로 묶어 이해할 수 있다.
- 대규모의 이미지-텍스트 쌍 데이터쌍으로 학습되어 strong sematic prior를 얻을 수 있다.
- 단점
- 주어진 reference set에 존재하는 대상의 모습을 모방하는 능력이 부족하다.
- 같은 대상을 다른 맥락의 환경에 합성하는 능력이 부족하다.
- 단점에 대한 이유
- output domain의 표현이 제한되었다. 즉, 학습된 모습만을 기반으로 이미지를 생성한다는 것이다.
- shared language-vision 공간을 사용하는 모델이라 할지라도 주어진 대상을 정확하게 재구성하지 못한다.
2.2. 논문에서 제시하는 모델: “personalization” of text-to-image diffusion models
- 목표: language-vision dictionary을 확장하여 주어진 대상과 단어를 결합하여 사용자가 원하는 대상이 합성된 이미지를 생성할 수 있도록 하는 것이다.
- 따라서 새로운 dictionary를 사용하여, 주어진 대상을 their key identifying features를 유지하며 다양한 환경에서 합성할 수 있다.
-
방식

- 주어진 대상이 포함된 이미지 3~5장이 주어지면,
- 주어진 대상을 unique identifier으로 변환하여 output domain에서 사용할 수 있도록, 합성될 수 있는 형태로 만든다.
- 즉, 주어진 대상을 unique identifier로 표현한다. unique identifier은 output domain 속의 representation이다.
- a pre-trained, diffusion-based text-to-image framework을 fine-tuning 한다.
3. Method
3.1. Text-to-Image Diffusion Models
- initial noise map $\epsilon \sim N(0,I)$ 과 conditioning vector c 를 통해 이미지 $x_{gen}$ 을 생성한다.
- $x_{gen} = \hat{x}_θ(\epsilon, c)$
-
squared error loss를 사용하여 잠재변수 $z_t$ denoising을 학습한다.
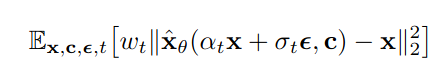
- 잠재변수 $z_t$ ⇒ $z_t := α_tx + σ_t\epsilon$
- $x$ ⇒ ground-truth image
- c ⇒ conditioning vector
- $\alpha_t, \sigma_t, w_t$ ⇒ noise schedule과 sample quality를 조절한다.
- 잠재변수 $z_t$ ⇒ $z_t := α_tx + σ_t\epsilon$
3.2. Personalization of Text-to-Image Models
- 대상에 대한 few-shot dataset으로 모델을 fine-tuning 한다.
- 주의할 점
- overfitting & mode-collapse
- 방법:
-
아래의 diffusion loss를 사용하였더니, prior를 잊어버리거나, overfitting 없이, 새로운 정보를 output domain에 잘 통합시킬 수 있었다.
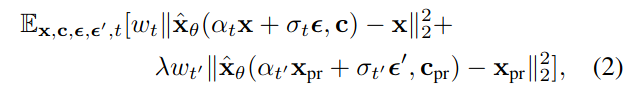
-
- 주의할 점
3.2.1. Designing Prompts for Few-Shot Personalization
- Designing Prompts 목표:
- (unique identifier, subject(대상))쌍을 diffusion model의 dictionary에 넣는 것이 목표이다.
- 방식:
- 간단한 description을 만들기 위해, 모든 input 이미지를 “a [identifier] class noun”의 형태로 레이블링하였다.
- [identifier]: subject와 매핑된 unique identifier이다.
-
- ⇒ cat, dog, watch, etc.
- class descriptor는 User가 직접 지정하거나 classifier를 통해 얻을 수 있다.
- 간단한 description을 만들기 위해, 모든 input 이미지를 “a [identifier] class noun”의 형태로 레이블링하였다.
- class descriptor(class noun)를 사용하는 이유:
- class의 prior를 subject와 묶기 위해서
- class descriptor를 사용하지 않으면, 학습 시간이 늘어나고, 성능이 좋지 못하다는 것을 발견하였기 때문이다.
- 따라서 특정 class의 prior와 unique identifier를 결합하여 visual prior으로 특정 subject를 새로운 포즈와, 표현을 생성할 수 있도록 한다.
3.2.2. Rare-token Identifiers
- 목적: identifier가 너무 strong한 prior를 가지고 있지 않도록 확률을 최소화하기
- 방법
- rare 토큰 선택
- vocabulary에서 rare-token 찾고, a sequence of rare token identifiers 얻기
- $f(\hat{V})$: a sequence of rare token identifiers
- sequence 길이는 짧은 것이 더 좋은 성능을 낸다.
- vocabulary에서 rare-token 찾고, a sequence of rare token identifiers 얻기
- 토큰을 text space로 변환
- identifier를 잘 나타내는 텍스트로 변환된다. - uniform random sampling of tokens과 tokens in the T5-XXL tokenizer를 사용하는 것이 좋은 성능을 냈다.
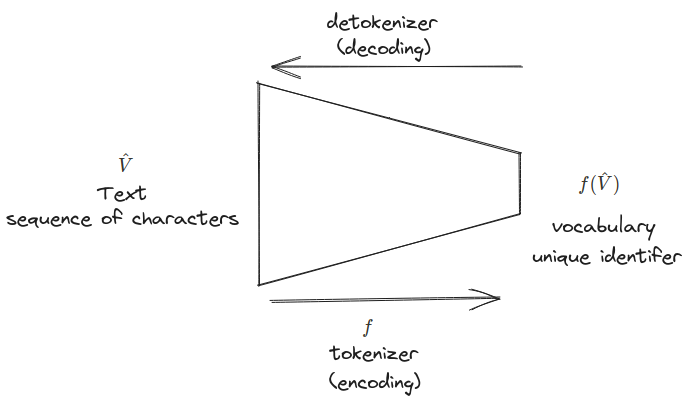
- $f$ : tokenizer; 문자 시퀀스를 토큰들로 매핑해주는 function
- $\hat{V}$ : decoded된 text
- rare 토큰 선택
3.3. Class-specific Prior Preservation Loss
- 목적: few-shot fine-tuning diffusion model
- 문제
- 언어 모델을 fine-tuning하면 language drift가 발생하는 경향이 있다.
- Language drift는 언어의 구문, 의미적인 knowledge를 잃는 것이다.
- diffusion model를 오랫동안 fine-tuning하게되면, diffusion의 특징인 output 다양성이 줄어들 수 있다.
- 언어 모델을 fine-tuning하면 language drift가 발생하는 경향이 있다.
- 해결: autogenous class-specific prior preservation loss 적용
- 다양성을 올려주고, language drift를 막을 수 있다.
- frozen pre-trained diffusion model 생성된 이미지를 레이블로 삼아 모델을 fine-tuning 한다.
⇒ few-shot fine-tuning 할 때, prior를 유지할 수 있도록
- frozen pre-trained diffusion model로 이미지를 생성하는 수식
- $x_{pr} = \hat{x}(z_{t_1} , c_{pr})$
- $x_{pr}$ : frozen pre-trained diffusion model로 생성된 이미지
- $c_{pr} := Γ(f (“a[class \space noun]”))$ : conditioning vector
- $z_{t_1} \sim N(0,I)$ : random initial noise
- $x_{pr} = \hat{x}(z_{t_1} , c_{pr})$
- frozen pre-trained diffusion model로 이미지를 생성하는 수식
-
Loss
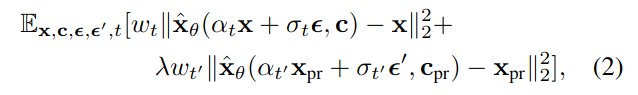
-
위 Loss의 앞부분은 text-to-image diffusion model의 Loss이다. (Reconstruction Loss)
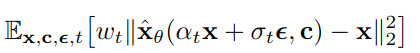
-
두 번째 부분의 Loss는 논문에서 제시하는 prior-preservation term이다. (Class-Specific Prior Preservation Loss)
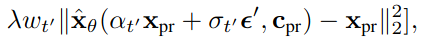
- frozen pre-trained diffusion model 로 생성된 이미지를 레이블로 삼아 모델을 fine-tuning 한다.
- $x_{pr}$ : frozen pre-trained diffusion model로 생성된 이미지
- $λ$: relative weight을 조절한다.
- frozen pre-trained diffusion model 로 생성된 이미지를 레이블로 삼아 모델을 fine-tuning 한다.
-
- prior-preservation loss로 인해 학습을 오랫동안해도 overfitting의 위험이 없다. - 하이퍼파라미터 설정 ⇒ good result - λ=1로 1000번 반복 - Imagen: learning_rate: $10^{-5}$ - Stable Diffusion: learning_rate: $5\times 10^{-6}$ - subject dataset size: 3~5개 - 학습 시간 - 5 minutes on one TPUv4 for Imagen - 5 minutes on a NVIDIA A100 for Stable Diffusion
4. Experiments
4.1. Dataset and Evaluation
4.1.1 Dataset

- 30개의 subject 수집
- backpacks, stuffed animals, dogs, cats, sunglasses, cartoons, etc.
- 2개의 카테고리로 분류 (objects & live subjects/pets)
- 21개가 objects, 9개가 live subjects/pets로 분류됨
- 25개의 prompts 수집
- 20 recontextualization prompts
- 10 recontextualization
- 10 accessorization
- 5 property modification prompts for live subjects/pets
- 20 recontextualization prompts
- 평가 데이터셋: 총 3,000 image 생성
- subject와 prompt 하나 당, 4개의 이미지 생성 ⇒ 3,000 = 30254
4.1.2. Evaluation Metrics
- subject fidelity(subject 디테일 보존 여부) 측정 기준 ⇒ 2개 지표 사용
- CLIP-I
- average pairwise cosine similarity between CLIP [52] embeddings of generated and real images.
- 다른 대상에 대한 구별 척도로는 사용할 수 없다. ⇒ DINO 사용
- DINO
- average pairwise cosine similarity between the ViTS/16 DINO embeddings of generated and real images.
- the self-supervised training objective encourages distinction of unique features of a subject or image.
- CLIP-I
- prompt fidelity
- CLIP-T
- average cosine similarity between prompt and image CLIP embeddings.
- CLIP-T
4.2. Comparisons
4.3. Ablation Studies
4.3.1. Prior Preservation Loss Ablation
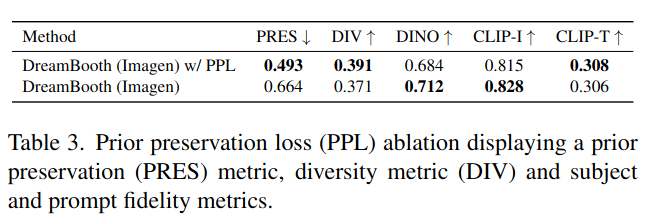
- 15개의 subject로 Imagen을 fine-tuning 하였다.
- prior preservation loss(PPL)를 적용한 fine-tuning
- prior preservation loss를 적용하지 않은 fine-tuning
- prior preservation metric (PRES): average pairwise DINO embeddings between generated images of random subjects of the prior class and real images of our specific subject
- PRES가 높을 수록 prior의 collapse를 의미한다. 즉, 낮을 수록 좋다.
- diversity metric (DIV): average LPIPS [73] cosine similarity between generated images of same subject with same prompt
4.3.2. Class-Prior Ablation
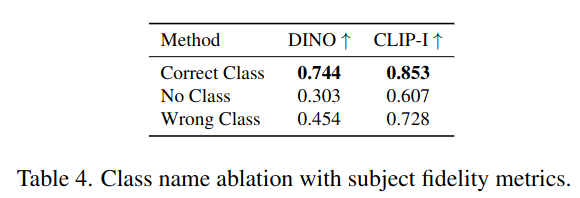
- 5개의 subject로 Imagen을 fine-tuning 하였다.
- no class noun
- a randomly sampled incorrect class noun
- correct class noun
⇒ 셋 중 correct class noun를 적용한 모델이 **가장 성능이 좋았다.
4.4. Applications
4.4.1. Recontextualization
- 선글라스, 가방, 화병에 대한 re-contextualization의 결과
- “a V [context description]” 프롬프트 사용
- 주어진 대상에 대해서. 다양한 이미지를 생성할 수 있다.
- 주어진 대상의 디테일을 보존하면서, 배경과 대상 간의 interaction이 가능하다.
4.4.2. Art Rendition
- Art Rendition: 원본 작품을 다른 형태나 스타일로 재구성한 것
- 주어진 대상을 가지고 유명한 화가의 스타일을 art rendition한 결과
- “a painting of a V in the style of [famous painter]” 또는 “a statue of a V in the style of [famous sculptor]” 프롬프트 사용

- 화가의 스타일을 잘 모방한 것을 알 수 있다.
4.4.3. Text-Guided View Synthesis
-
대상의 다양한 view-point 구현 가능

- view-point에 따라 배경도 변한다.
- 고양이 이마의 복잡한 무늬도 보존 가능하다는 것을 알 수 있다.
4.4.4. Property Modification

- 첫 번째 줄은 color 수정
- “a [color] [V] car” 프롬프트 사용
- 두 번째 줄은 주어진 대상인 dog을 다른 동물로 바꾼 것이다.
- “a cross of a [V] dog and a [target species]” 프롬프트 사용
4.4.5. Accessorization

- 주어진 대상 강아지에게 악세사리, 옷 등을 입힌다.
- “a [V] dog wearing a police/chef/witch outfit” 프롬프트 사용
- 주어진 대상과 옷, 악세사리와의 interaction이 현실적인 interaction이 가능하다는 것을 알 수 있다.
5. Conclusion
- Dreambooth는 개인 맞춤의 합성, 생성을 위한 다양한 effective tool을 제공한다.
- 일반적인 text-to-image model에서는 특정 attributes으로 편항되는 문제를 해결하였다.
- 따라서 더 좋은 성능으로 유저가 원하는 대상의 재구성이 가능하다.
댓글남기기