
[논문 리뷰] AudioToken: Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation
이 논문은 Text를 조건으로한 Diffusion 모델을 Audio-to-Image generation으로 변화시킨 논문이다.
이 논문을 읽게되는 계기는 AudioToken 모델의 Audio Embedding 과정에서 오디오의 Temporal 길이와 정보가 그대로 유지가 되는지, 임베딩 과정에서 오디오 Feature의 Shape을 알아보고자 읽게 되었다. 따라서 Method 중에서도 Audio Embedding 부분만 간략하게 정리해보았다.
1. Abstract
이 논문에서는 text-to-image generation을 위해 만들어진 모델을 사용하여 audio-to-image generation을 하려고 한다.
- 사전 학습된 오디오 인코딩 모델 사용한다.
- 사전 학습된 오디오 인코딩 모델 사용해서 오디오를 하나의 토큰으로 만든다.
- 이러한 방식은 오디오와 텍스트 사이를 적응하는 layer로 여겨진다.
2. Adaptation of text-conditioned models
2.1. AudioToken
- Problem: 고화질의 이미지를 생성하는 모델은 주로 대규모의 text-image 쌍에 의존하여 text를 통해 이미지를 생성한다.
- AudioToken 모델은 오디오 신호를 text 공간에 집어넣어, 새로운 생성 모델을 학습하는 것이 아닌, 기존의 text-conditioned model 들을 사용해서 audio토큰 기반으로 이미지를 생성할 수 있다.
- 모델의 목표: 오디오 시그널을 텍스트 conditioning 공간으로 인코딩하고자 한다.
- 즉, 오디오 시그널 a를 text conditioning과 연관시켜야한다
- Input: Short Video input (i,a)
- i: 비디오의 하나의 프레임
- a: i에 해당하는 audio recording
- Output: $p(i|a)$
- audio를 넣었을 때, 하나의 프레임 출력
3. AudioToken의 구조
3.1. Input & Output
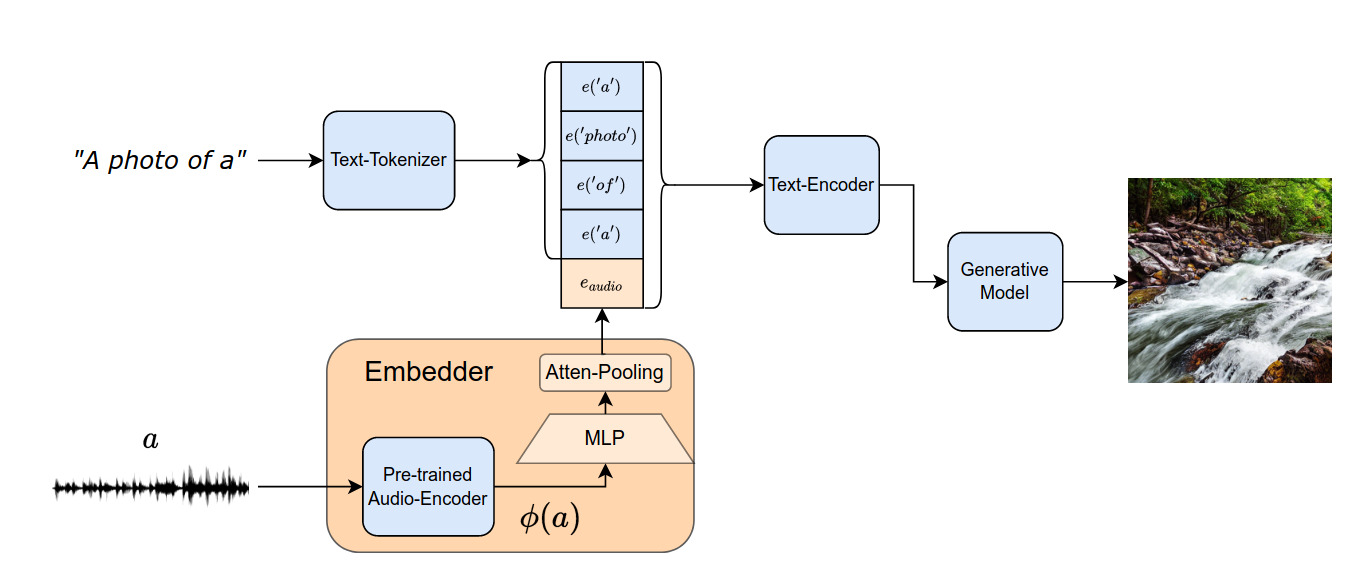
- “A photo of a”를 transformer 모델을 이용해서 text를 인코딩한다.
- $e_{text}$ 와 $e_{audio}$ 를 concat 한다.
- $e_{text}$ 차원: 4x $d_a$ ⇒ $d_a$ 는 텍스트 입력의 embedding 차원
- $e_{audio}$ 차원: $d_a$ ⇒ $d_a$ 는 텍스트 입력의 embedding 차원
- $e_{audio}= Embedder(a)$ 를 통해서 $e_{audio}$ 를 얻을 수 있다.
- Embedder는 [Pre-trained Audio-Encoder] + [small projection network]로 구성되었다.
3.2. Embedder Network와 Optimization process
3.2.1. Embedder Network
- Embedder 파라미터만 훈련되고 나머지는 freeze한다.
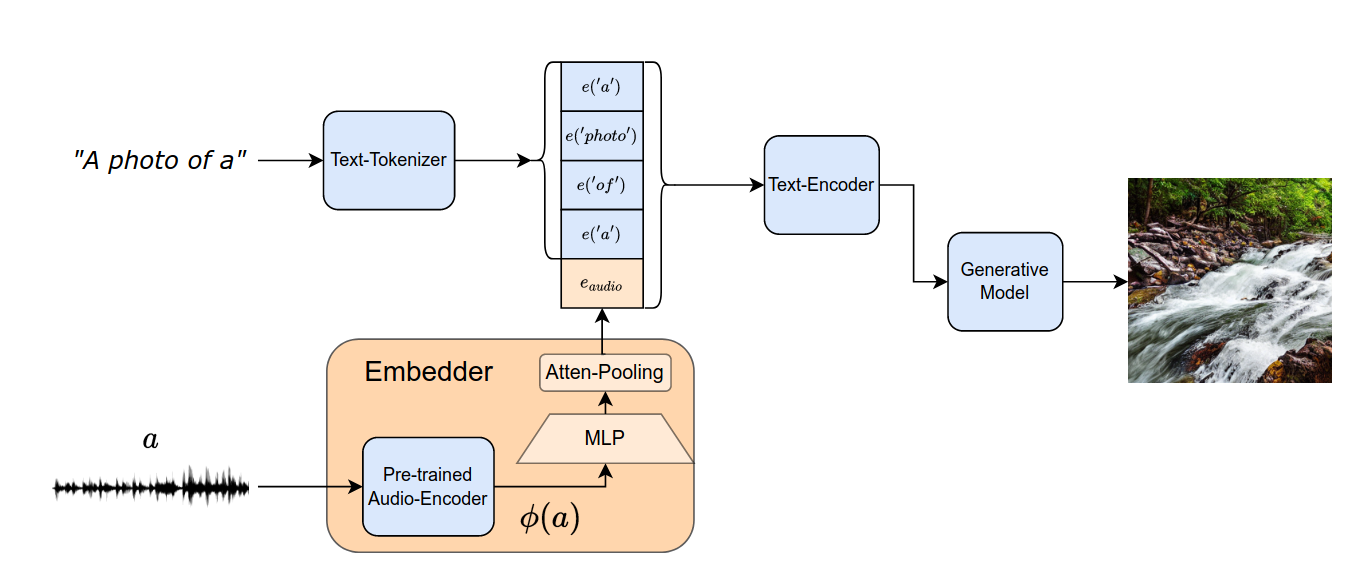
- Pre-trained Audio-Encoder
- A pre-trained text encoder extracts tokens created by a tokenizer and the audio token
- Generative Model
- 입력으로 concatenated tensor를 받는다.
- Audio encoding
- $φ$ : pre-trained audio classification network
- 이 network의 마지막 layer는 classification인데, 이 layer는 오디오의 정보를 손실시킬 수 있음 → 그래서 마지막 layer 이전의 layer들과 마지막 히든 layer(4, 8, 12번째 layers 중에 선택)을 concatenate한다.
- 그 결과 temporal embedding of the audio인 $φ(a) ∈ R^{\hat{d}×n_a}$ 가 도출된다.
- $n_a$: temporal audio dimension
- 그 다음 temporal embedding of the audio인 $φ(a)$ 얘를 textual embedding 공간으로 projection하기 위해서 학습시킨다. 2개의 linear layer에 $φ(a)$ 를 집어넣는다.
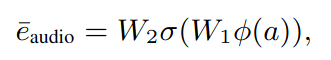
- $W_2 ∈ R^{\hat{d}× \hat{d}}$
- $W_1 ∈ R^{\hat{d}× d_{audio}}$
- σ: GELU activation function
- 마지막으로 attention-pooling을 넣어 temporal dimentsion을 축소시킨다.
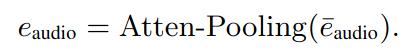
- $φ$ : pre-trained audio classification network
3.2.2. Optimization
- Embedder network 내에 있는 MLP와 attentive pooling layers만 학습한다.
- pre-trained audio network와 generative network는 frozen한다.
- Loss function
- Overall Loss Function
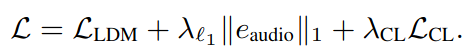
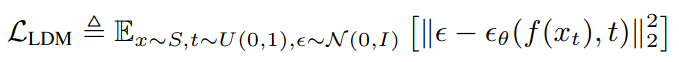
- Overall Loss Function
댓글남기기