
[논문 리뷰] AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models
오늘은 AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models 라는 논문에 대해 알아볼 것이다.
읽기 전에 제목만 보자면 텍스트 명령어에 따라서 오디오를 수정하는 것인가 생각이 든다.
Abstract를 읽어보며 어떤 instruction를 사용하여 오디오를 어떻게 Editing하는 논문인지 예시를 통해 살펴보자
Abstract
Audio editing은 배경 소리 효과 넣기, 음악 악기 대체, 손상된 오디오 복구 등과 같은 목적으로 적용될 수 있다.
최근에 몇몇 Diffusion을 사용한 하는 모델들은 Zero-Shot을 기반으로한 Audio Editing을 구현하였다. 대부분 오디오에 대한 텍스트(description)을 기반으로 diffusion noising, denoising하는 방식을 사용했다.
하지만 이전 모델에는 아래와 같은 문제가 발생한다.
- 이전 모델들은 Editing task에 맞게 훈련되지 않았으며, 좋은 editing 효과를 보장하지 못한다.
- 또한 수정이 필요하지 않은 부분을 잘못 수정할 수 있다.
- 오디오에 대해 완전한 description이 있어야 모델을 훈련시킬 수 있다.
위와 같은 문제를 해결하고자 논문에서는 AUDIT을 제안하였다.
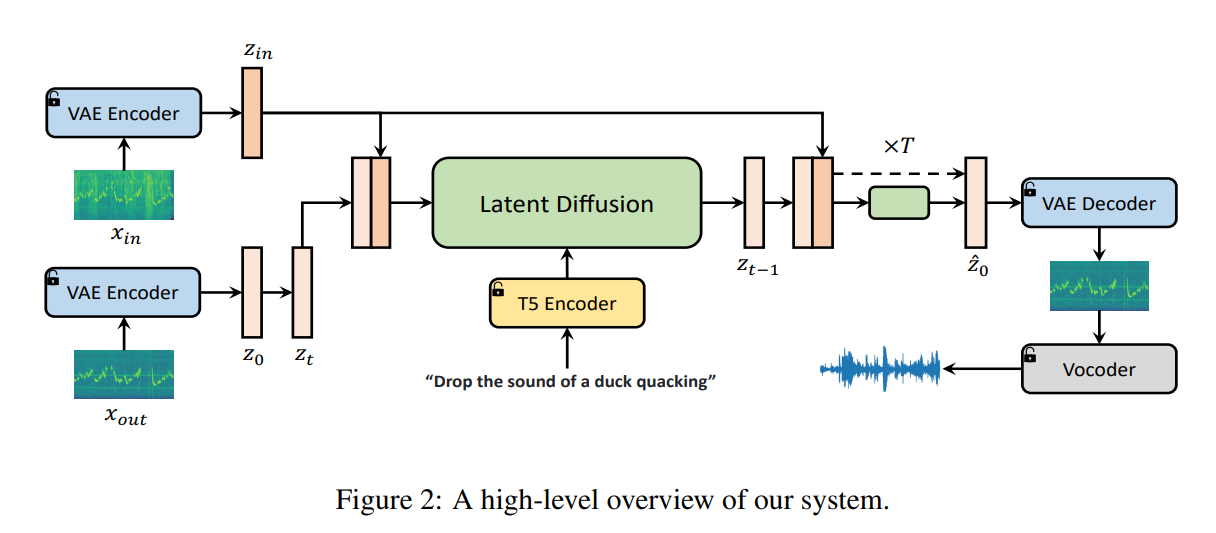
AUDIT은 instruction-guided audio editing model인데, latent diffusion 모델을 기반으로 만들어졌다.
아래와 같이 AUDIT은 세가지 주요 구성 요소로 이루어져있다.
- triplet training data
- instruction (text)
- input audio
- output audio (이 부분이 edited(수정된) audio이다.)
- input과 output audio를 비교하며, 수정되어야하는 segment만을 수정하도록 자동으로 학습할 수 있다.
- edit instructions만을 필요로 한다. 즉, 전체 오디오에 대해 전반적인 descriptions이 text input으로 들어갈 필요없다.
결과적으로, AUDIT은 오디오 에디팅 Task (오디오 추가, 제거, 대체, 손상된 부분 재구성, 초고해상도 소리 등)에서 객관적, 주관적 지표 모두에서 SOTA를 달성했다.
Demo 샘플들을 구경해보자
- AUDIT 구조는 VAE, T5 Text Encoder, Diffusion network으로 구성된다.
- audio input의 mel-spectrogram과 텍스트 instructions이 입력으로 들어가고, edited audio가 output으로 생성된다.
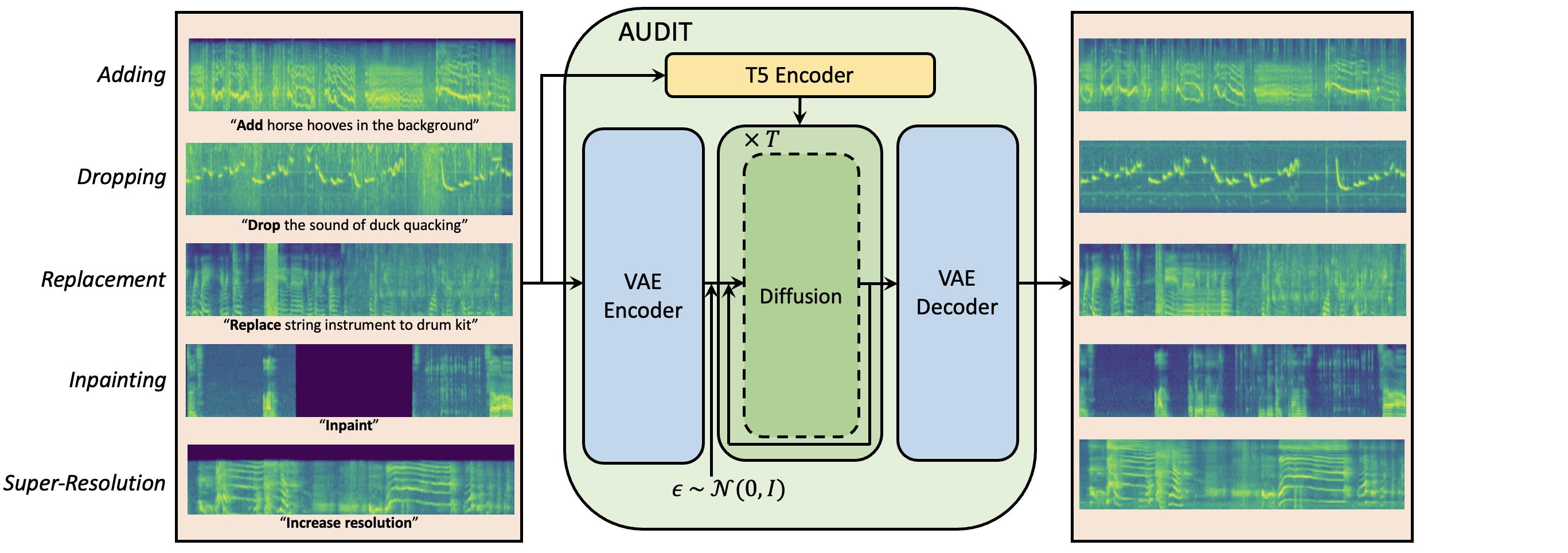
ADD
- input 오디오에 sound event를 더하는 Task이다.
Text Instruction: “**Add** horse hooves in the background”- 텍스트 instruction과 수정이 필요한 오디오가 들어가면, 텍스트는 T5 Text Encoder를 거져서 Diffusion network로 들어가고, 오디오는 VAE Encoder를 거쳐 Diffusion network에 들어간다. 그리고 VAE Decoder를 거쳐 말발굽 소리가 배경소리로 들어간 수정된 오디오 파일이 생성된다.
- 예를 들어서 “A baby is crying”이라는 오디오가 input으로 들어가면, “A baby is crying while thundering in the background.”라는 semantic information이 추가된 output audio로 변환된다.
- 중요한 점
- 생성된 output 오디오는 input 오디오의 semantic content와 새롭게 추가된 semantc content를 포함하는 것 뿐만 아니라
- input 오디오는 output audio에서 가능한 변화되지 않아야한다.
DROP
- Drop Task는 하나 이상의 sound event를 input 오디오에서 제거해야한다.
Text Instruction: “**Drop** the sound of duck quackling”- 예를 들어서 “A man giving a speech while a dog barking”이라는 오디오에서 “dog barking”이라는 sound event를 제거한다면, “A man giving a speech”라는 semantic description을 포함하는 output 오디오가 나온다.
Replacement
- Replacement Task는 input 오디오의 한 가지 sound event를 다른 sound event로 대체해야한다.
Text Instruction: “Replace string instrument to drum kit”- 예를 들어서 “the sound of gun shooting and bell ringing” 캡션이 달린 오디오에서 “bell ringing”라는 sound event를 ‘fireworks’라는 sound event로 바꾼다면, “the sound of gun shooting and fireworks”라는 description을 포함한 output 오디오가 나온다.
Inpainting
- Inpaint Task는 masked된 오디오 segment를 context나 제공된 textual description을 기반으로 생성 예측한다.
Text Instruction: “Inpaint”
Super-Resolution
- Super-resolution Task는 저품질의 input 오디오의 고주파 정보를 완성하는 작업으로 볼 수 있다. (저샘플링 입력을 고샘플링 출력으로 변환하는 작업)
Text Instruction: “Increase resolution”
Text-to-Audio Generation
- AUDIT은 text-to-audio 생성 분야에서도 FD, KL, IS의 객관적인 지표에서 최고의 성능을 달성했다.
- 위 논문에서는 FD 점수를 23.31에서 20.19로 낮추고, KL 점수는 1.59에서 1.32만큼 낮추고, 그리고 IS 점수는 8.13에서 9.23로 상승시켰다.
댓글남기기