
[Computer Vision] 1. Introduction to Convolutional Neural Networks for Visual Recognition
스탠포드대학에서 발표한 CNN 강의 영상을 듣고 자료를 정리했습니다.
Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition
Computer Vision이란?
컴퓨터 과학의 연구 분야 중 인간이 시각적으로 하는일들을 대행하도록 시스템을 만드는 것이다.
Vision의 역사
생물학적 Vision
빅뱅을 시작으로 생물이 진화하면서 현재 Vision은 동물의 큰 감각 체계가 되었다.
인간의 대뇌 절반 가량의 뉴런이 시각 처리에 관여할 정도로 큰 부분을 차지한다.
인공적 Vision
1600년대 카메라인 Obscura 발명을 시작으로 카메라 기술이 발전하였고,
지금까지 가장 많이 사용하는 센서중 하나이다.
Computer Vision의 역사
1. 포유류의 시각처리방식 연구(Hubel & Wiesel, 1959)
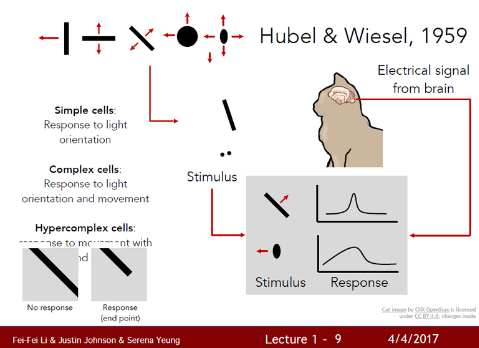
고양이의 뇌에 전기적 신호를 보내고 1차 시각 피질에 다양한 종류의 세포가 있음을 발견했다.
Simple cells
1차 시각 피질에서 가장 중요한 세포이며, 시각처리가 시작되는 곳이다.
특정한 방향으로 이동할 때 oriented edge에 반응한다.
즉, 시각 처리가 단순한 구조로 시작하여 점점 복잡해지는 것을 발견하였다.
2. Block World(Larry Roberts, 1963)

사물의 특징을 얻기 쉽도록 실제 사물을 기하학적인 모양으로 단순화하는 모형을 제시하였다.
3. The Summer Vision Project(MIT, 1966)
4. Hierachical Model(David Marr, 1970s)

우리의 눈에 인식된 이미지를 3D로 표현하기 위한 3단계 과정을 정의하였다.
5. Generalized Cylinder(1979), Pictorial Structure(1973)

모든 물체는 단순한 기하학적 구조로 이루어졌다
6. 이미지 인식을 객체 분할로 시작(1980s)

배경: 실제 세계를 단순화된 구조로 인식하기 어려움
이미지의 픽셀들을 그룹화하여 의미있는 영역으로 분할하는 방식으로 이미지 분류를 하였다.
7. Face Detection(Paul Viola, Michael Jones, 2001)

AdaBoost algorithm 사용 & 카메라 기술 발전 → 실시간 얼굴 인식 가능해짐
8. Shift & Object Recognition(David Lowe, 1999)

같은 객체임에도 불구하고 카메라 각도에 따라서 이미지를 다르게 인식하는 문제가 발생한다.
이에 연구 방향이 객체 분할에서 객체 인식으로 바뀌었다.
객체를 인식하기 위한 중요한 특징을 찾고 → 유사한 객체와 그러한 특징들을 맞춰보며 객체를 인식하는 방식을 사용한다.
ImageNet Project
목적
-
세상 모든 이미지 분류
-
기계학습의 Overfitting 문제(고차원 데이터 & 훈련 세트 부족) 극복

2012년 ImageNet 국제대회 ILSVRC 개최에서 CNN(Convolutional Neural Network) 도입으로 기존 28.2%, 25%의 오류율을 16.4%로 오차율이 급격히 감소되었다.
댓글남기기